O espelhamento de porta é uma técnica que permite que o Switch efetuar a cópia dos pacotes de uma porta para outra porta.
Essa técnica é bastante utilizada quando precisamos analisar o comportamento da rede, como por exemplo, para identificação de vírus, acessos “estranhos”, comportamento de aplicações, serviços, etc.
A principal função de qualquer protocolo de roteamento dinâmico é auxiliar os roteadores no processo de encaminhamento dos pacotes com a utilização do melhor caminho para um determinado destino. As informações inseridas na tabela de roteamento incluem principalmente: a rede de destino, a forma de aprendizado da rota e o próximo salto, para endereços de rede unicast.
Entretanto quando um roteador recebe um pacote com endereço IPv4 multicast, ele não consegue encaminhar o pacote utilizando a tabela de roteamento IPv4 unicast pois os endereços multicast não são inseridos na tabela.
Os roteadores podem encaminhar os pacotes multicast somente através dos protocolos de roteamento como o multicast dense-mode e sparse-mode, que se utilizam da tabela de roteamento unicast para encaminhamento do trafego.
Nesse artigo abordaremos o processo dense-mode para encaminhamento de tráfego IPv4 multicast.
Dense-mode
Os protocolos de roteamento multicast dense-mode assumem que um grupo multicast será solicitado em cada sub rede por ao menos um receptor (receiver). O design do dense-mode instrui o roteador para encaminhar o tráfego multicast em todas interfaces configuradas com dense-mode. Há algumas exceções para prevenção de loop, como validar se o endereço de origem do pacote, possui uma rota no roteador para interface que recebeu aquele pacote (RPF) e então nesse caso ele enviaria uma cópia do trafego multicast para todas as interfaces exceto aquela que o pacote foi recebido.
Os roteadores com dense-mode entendem que todas as sub rede desejam receber uma cópia do tráfego multicast, exceto quando outros roteadores (downstream) não desejam receber o tráfego para aquele grupo ou quando um host diretamente conectado não deseja juntar-se ao grupo multicast. Quando essas condições são encontradas, os roteadores enviam mensagens de poda (prune message) para cessar o tráfego naquele segmento.
Falando do RPF
Os protocolos de roteamento multicast usam a verificação de encaminhamento inverso (RPF – Reverse Path Forwarding) para garantir a entrega fluxo multicast criando entradas de roteamento multicast com base nas rotas unicast existentes ou rotas multicast estáticas. A verificação de RPF também ajuda a evitar loops de dados. Um fluxo multicast de entrada não será aceito ou encaminhado a menos que o fluxo seja recebido em uma interface de saída para a rota unicast no cabeçalho de origem do pacote.
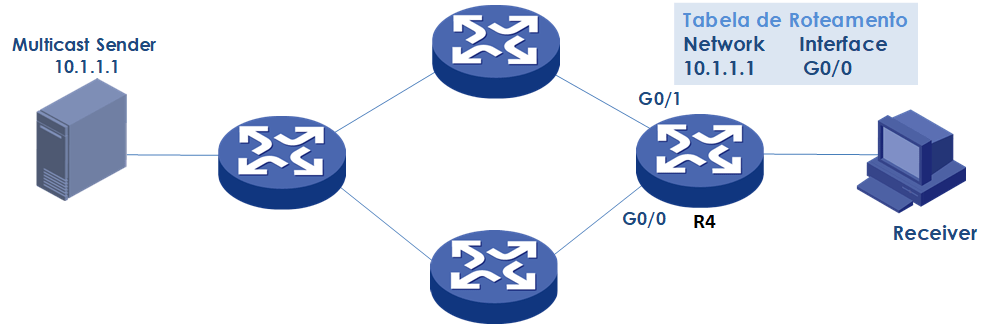
No exemplo abaixo, o Roteador R4, irá apenas aceitar e encaminhar o fluxo multicast gerado pelo Multicast Sender 10.1.1.1 para o receiver, se recebido pela interface G0/0.
Falando um pouco mais do PIM Dense-mode…
O protocolo de roteamento multicast PIM (Protocol Independent Multicast) Dense-mode, define uma serie de mensagens e regras para a comunicação eficiente de pacotes multicast; ele atua de forma independente do protocolo de roteamento IPv4 unicast, mas utilizando a tabela de roteamento unicastpara validação RPF. O protocolo PIM simplesmente confia na tabela de roteamento unicast.
O PIM estabelece relacionamento com seus vizinhos utilizando mensagens Hello que são enviadas a cada 30 segundos utilizando o protocolo IP 103 e o endereço 224.0.0.13 (All-PIM-Routers), o holdtimer geralmente é três vezes o tempo do hello. Caso o roteador não receba a mensagem hello durante o holdtime, ele considera a perda de adjacência com o vizinho.
Source-Based Distribution Tree
Quando um roteador PIM-DM recebe um pacote multicast, ele primeiro executa uma validação RPF. Uma vez que a validação confirmada, o roteador encaminha uma cópia do pacote multicast para todos os roteadores vizinhos com PIM-DM, exceto aquele que ele recebeu o pacote. Cada roteador PIM-DM repete todo o processo e inunda a rede com o trafego do grupo multicast, até o ultimo roteador da topologia – que não possui roteadores vizinhos abaixo (downstream).
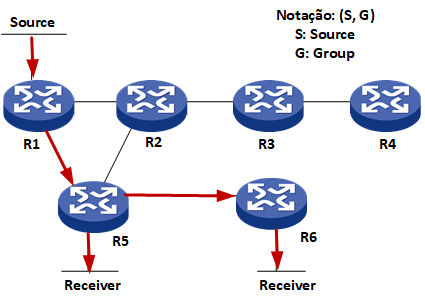
Todo esse processo é chamado source-based distribution tree, shortest path tree (SPT) ou source tree. O tree (arvore) define o caminho entre source que origina o trafego multicast e o receiver, que recebe uma cópia do trafego multicast. O source é considerado a raiz e as sub redes como galhos e folhas das arvores.
O PIM-DM pode ter diferentes “arvores de distribuição” para cada combinação da origem do grupo multicast, pois o SPT irá se basear na origem e localização dos hosts de cada grupo multicast. A notação (S,G) refere-se a cada particular SPT, onde S é o endereço IP de origem e G é o endereço do grupo multicast, como por exemplo (192.168.1.10,226.1.1.1).
Fazendo a poda – Prune message
Quando uma sub rede não precisa de uma cópia do trafego multicast o PIM-DM define um processo para os roteadores remover suas interfaces do SPT utilizando as mensagens PIM Prune.
A mensagem PIM Prune é enviada por um roteador a um segundo roteador para remover o link em que a poda é recebida para um particular (S,G) SPT.
Em razão do PIM-DM querer encaminhar o trafego para todas as interfaces (com o PIM configurado), após 3 minutos de receber uma mensagem de poda, ele retorna o encaminhamento de trafego multicast naquela interface. Caso o roteador que enviou a mensagem Prune não queira continuar recebendo o trafego multicast, ele enviara novamente a mensagem de poda. O processo de encaminhamento e poda ocorre periodicamente. As ramificações (sub-redes) podadas reiniciam o encaminhamento multicast quando o estado de poda expira e, em seguida, os dados são inundados novamente nesses segmentos de rede e, em seguida, os ramos são cortados novamente…
Graft
Quando um receptor em um segmento podado anteriormente se une a um grupo multicast, uma opção é esperar que os links podados, expirem. Entretanto, para reduzir a latência do join a um grupo multicast, O PIM-DM usa um mecanismo chamado graft para retomar o encaminhamento de dados para esse segmento, sem esperar que o tempo do prune expire.
Uma vez que o roteador envie a mensagem graft para um vizinho, que havia enviando uma mensagem prune anteriormente, o roteador irá encaminhar a porta para o estado de encaminhamento para determinado (S,G) SPT.
Assert
O mecanismo de assert desliga os fluxos de multicast duplicados para a mesma rede, onde mais de um roteador multicast encaminha o trafego para a LAN, ao eleger um encaminhador multicast exclusivo na rede local. Seguindo seguinte processo:
1. O roteador anuncia a menor distancia administrativa do protocolo de roteamento utilizado para aprender a melhor rota.
2. Se houver empate, o roteador escolhido terá a menor métrica para a origem
3. Se houver um novo empate, o roteador escolhido será o que tiver o maior endereço IP na interface local.
Exemplo de Configuração do PIM DM
No cenário abaixo, uma máquina da rede 192.168.2.0/24 deseja receber o fluxo multicast com o endereço 239.1.1.1. O Sw2 está configurando com OSPF e PIM o estabelecimento do roteamento Unicast e Multicast da rede.
Configuração de Sw2
#
vlan 2
vlan 12
#
interface Vlan-interface2
ip address 192.168.2.1 255.255.255.0
igmp enable
! Habilitando a interface para troca de mensagens IGMP
#
interface Vlan-interface12
ip address 192.168.12.2 255.255.255.0
pim dm
! Habilitando o PIM DM para Roteamento Multicast com o R1
#
ospf 10
area 0.0.0.0
network 192.168.2.0 0.0.0.255
network 192.168.12.0 0.0.0.255
! Configurando o OSPF para o Roteamento Unicast
#
Para aqueles que estão acostumados com o comando “logging synchronous” no IOS existe a opção “info-center synchronous” para o Comware
[4800G]info-center synchronous
% Info-center synchronous output is on
Segue o output com o comando habilitado:
[4800G]interface GigabitEthernet 1/0/
%Apr 26 09:25:32:201 2000 4800G IFNET/4/LINK UPDOWN:
GigabitEthernet1/0/2: link status is DOWN
[4800G]interface GigabitEthernet 1/0/
Segue o output com o commando desabiiltado (percebam o comando “em digitação” fica oculto e assim comprometendo a configuração, tornando suceptível a erros:
[4800G]interface GigabitEthernet 1/0/
%Apr 26 10:42:36:371 2000 4800G IFNET/4/LINK UPDOWN:
GigabitEthernet1/0/2: link status is UP
A utilização de VRF (Virtual Routing and Forwarding) permite a criação de tabelas de roteamentos virtuais em Switches e Roteadores; independentes da tabela de roteamento “normal”(geralmente chamada de tabela de roteamento global [Global Routing Table]).
Da mesma forma como a utilização de VLANs em Switches Ethernet permitem a divisão de dominios de broadcasts e mapeamentos da tabela MAC, a utilização de VRF permite a virtualização da tabela de roteamento. Nos Switches e Roteadores utilizando o Sistema Operacional Comware (3Com, H3C e HPN) a feature é chamada de “vpn-instance“.
Apesar da tecnologia VRF ter a sua função vinculada às redes MPLS (por ser largamente utilizado em Provedores e Data Centers) há a possibilidade de criar tabelas de roteamento apenas para funções locais do Roteador, chamado de VRF-lite ou também Multi-VRF.
Você pode ser perguntar: “Mas por qual razão eu precisaria configurar outra tabela de roteamento em meu roteador?” Geralmente as empresas que prestam serviços de TI, monitoração de redes e serviços, “operadoras de links”, etc; precisam lidar com clientes que usam em sua maioria endereços da RFC1918 (endereços IPv4 privados) o que aumenta a probabilidade de mais de um cliente possuir endereços de rede IPv4 iguais (além do fator de segurança ) e a complexidade da divisão das redes usando NAT e ACL; a utilização de VRFs possibilita a independência das tabelas de roteamento, permitindo que uma tabela de rotas não possua roteamento com as outras (por padrão).
Segue abaixo o exemplo da configuração do cenário acima:
# Criando as VRFs (vpn-instance)
ip vpn-instance ABC
! criando a VRF chamada “ABC”
route-distinguisher 1:1
! configurando o RD
#
ip vpn-instance XYZ
route-distinguisher 2:2
#
Obs: a configuração do Route-distinguisher (RD) permite a extensão do endereço IPv4 para diferenciação, chamado de VPNv4. Os endereços VPNv4 são a combinação de endereços IPv4(32 bit) e o valor Route-distinguiser (64 bit).
# Com as VLANs criadas atribua a vpn-instance a interface VLAN
vlan 1
#
vlan 2 to 5
#
interface Vlan-interface2
ip binding vpn-instance ABC
! vinculando a VRF à interface VLAN
ip address 192.168.1.1 255.255.255.0
#
interface Vlan-interface3
ip binding vpn-instance ABC
ip address 192.168.2.1 255.255.255.0
#
interface Vlan-interface4
ip binding vpn-instance XYZ
ip address 192.168.1.1 255.255.255.0
#
interface Vlan-interface5
ip binding vpn-instance XYZ
ip address 192.168.2.1 255.255.255.0
#
# A configuração poderá ser atribuída a Switches e Roteadores,
# inclusive em interfaces em modo Routed.
Validando as vpn-instance criadas…
display ip vpn-instance
Total VPN-Instances configured : 2
VPN-Instance Name RD Create time
ABC 1:1 2013/10/20 18:35:42
XYZ 2:2 2013/10/20 18:36:04
Verificando as tabelas de roteamento da VRF e a tabela de roteamento global.
[SW1]display ip routing-table
Routing Tables: Public
Destinations : 2 Routes : 2
Destination/Mask Proto Pre Cost NextHop Interface
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0
! Na tabela global há somente o endereço de loopback 127.0.0.1
!
[SW1]display ip routing-table vpn-instance ABC
Routing Tables: ABC
Destinations : 6 Routes : 6
Destination/Mask Proto Pre Cost NextHop Interface
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0
192.168.1.0/24 Direct 0 0 192.168.1.1 Vlan2
192.168.1.1/32 Direct 0 0 127.0.0.1 InLoop0
192.168.2.0/24 Direct 0 0 192.168.2.1 Vlan3
192.168.2.1/32 Direct 0 0 127.0.0.1 InLoop0
! Rotas da VRF ABC
!
[SW1]display ip routing-table vpn-instance XYZ
Routing Tables: XYZ
Destinations : 6 Routes : 6
Destination/Mask Proto Pre Cost NextHop Interface
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0
127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0
192.168.1.0/24 Direct 0 0 192.168.1.1 Vlan4
192.168.1.1/32 Direct 0 0 127.0.0.1 InLoop0
192.168.2.0/24 Direct 0 0 192.168.2.1 Vlan5
192.168.2.1/32 Direct 0 0 127.0.0.1 InLoop0
! Rotas da VRF XYZ
Além do Roteamento para as interfaces diretamente conectadas é possível tambem separa as rotas estaticas e protocolos de Roteamento em processos independente para cada vpn-instance
# Exemplo de configuração de rota estatica por VRF
ip route-static vpn-instance ABC 0.0.0.0 0.0.0.0 192.168.1.254
ip route-static vpn-instance XYZ 0.0.0.0 0.0.0.0 192.168.1.100
# Criação de processos individuais do OSPF por VRF
[SW1]ospf 10 vpn-instance ?
STRING VPN Routing/Forwarding Instance (VRF) Name
Dica : Sempre configure o endereço IP após atribuir uma vpn-instance à uma interface, pois o dispositivo irá remover a configuração IP da interface.
[Router-LoopBack0]ip binding vpn-instance TESTE
All IP related configurations on this interface are removed!
Nos equipamentos baseados no Comware a configuração do RD é obrigatória na criação da VRF!
O comando display device manuinfo ajuda a descobrir remotamente qual o serial number (número serial) de Switches HP baseados no Comware.
Geralmente as etiquetas que vem coladas nos switches não-modulares – uma vez que os equipamentos já estão no rack – é bem complicada de se encontrar ou ler os caracteres bem pequenos em um ambiente escuro (pois é, a idade já chegou…).
Ps: geralmente a informação do Serial Number é utilizada para registrar o equipamento com o fabricante, solicitar garantia de suporte, inventário, etc.
A maneira como efetuamos o roteamento de pacotes baseado endereço de destino do cabeçalho IP possui algumas restrições que não permitem o balanceamento de tráfego de maneira granular de acordo com perfis das aplicações, dessa forma todos os pacotes são roteados para o mesmo lugar sem levarmos em conta a rede de origem, protocolo, etc.
A utilização de PBR, policy-based routing, permite ao engenheiro de rede a habilidade de alterar o comportamento padrão de roteamento baseando-se em diferentes critérios ao invés de somente a rede de destino, incluindo o endereço de rede de origem, endereços TCP/UDP de origem e/ou destino, tamanho do pacote, pacotes classificados com fins de QoS, etc.
Mas por qual razão utilizaremos PBR ?
O PBR pode ser utilizado em diversos cenários, para os mais diversos fins. No exemplo abaixo a rede 192.168.1.0/24 acessa a rede 172.16.0.1 com uma rota default configurada para o Link A, imaginando que uma segunda demanda surge para que a rede de homologação 192.168.2.0/24 acesse assim a Internet pelo Link A mas já o acesso para rede 172.16.0.1, deva ocorrer preferivelmente pelo link B. Nesse caso o PBR entraria para corrigir essa questão (lembrando que na tabela de roteamento o acesso para rede 172.16.0.1 é apontado para o Link A, criaríamos uma exceção somente para a nova rede).
Segue exemplo da configuração:
#
acl number 2000
rule 0 permit source 192.168.2.0 0.0.0.255
! ACL para match na rede 192.168.2.0
#
policy-based-route XYZ permit node 10
if-match acl 2000
apply next-hop 192.168.223.3
! PBR dando match na ACL 2000 e encaminhar o
! tráfego para o next-hop do link B
#
#
interface GigabitEthernet0/0/3
port link-mode route
ip address 192.168.12.2 255.255.255.0
ip policy-based-route XYZ
! Aplicando o PBR na interface Giga0/0/3
#
A implementação da PBR é bastante simples, ele é definido para ser configurado usando o processo policy-based routing que é muito similar a configuração de uma route-policy (route-map) . O tráfego a ser tratado pelo PBR será comparado (match) utilizando uma ACL e em seguida tem o novo destino ou parâmetros alterados usando um comando apply + atributo.
Se o pacote não corresponder à política de PBR ou se o encaminhamento baseado em PBR falhar, o dispositivo utilizará a tabela de roteamento para encaminhar os pacotes.
Outros parametros dentro do PBR
Entre os outros parametros do PBR está o output-interface, default-next-hop e o default-output-interface.
Output-interface: Esse comando permite atribuir a interface de saída do trafego ao invés do IP do next-hop.
Default-next-hop / default-output-interface:Se o processo de roteamento baseado na tabela de rotas falhar, o equipamento utilizará o default next hop ou default output interface definido no PBR para encaminhar os pacotes.
Ao utilizar qualquer combinação destes comandos dentro de um PBR os comandos são avaliados na seguinte ordem:
O PBR é uma ferramenta muito poderosa que pode ser usada para controlar os caminhos específicos de tráfego de rede, porém certifique-se de usar apenas PBR quando for necessário. Como muitas outras features oferecidas em qualquer tipo de roteador, elas são projetadas para um conjunto específico de circunstâncias, o mesmo e deve ser utilizado para esses fins para assim manter a eficiência.
O Ethernet Virtual Private Network (EVPN) é uma tecnologia VPN de Camada 2 VPN que fornece conectividade entre dispositivos tanto em Camada 2 como para Camada 3 através de uma rede IP. A tecnologia EVPN utiliza o MP-BGP como plano de controle (control plane) e o VXLAN como plano de dados/encaminhamento (data plane) de um switch/roteador. A tecnologia é geralmente utilizada em data centers em ambiente multitenant ( com múltiplos clientes e serviços) com grande tráfego leste-oeste.
A configuração do EVPN permite ao MP-BGP automatizar a descoberta de VTEPs, assim como o estabelecimento de tuneis VXLAN de forma dinâmica, a utilização de IRB (Integrated Routing and Bridging) anuncia tanto as informações de Camada 2 e 3 para acesso ao host, fornecendo a utilização do melhor caminho através do ECMP e minimizando flood do trafego multidestination (BUM: broadcast,unicast unknown e multicast) .
Em resumo o EVPN possui um address Family que permite que as informações de MAC, IP, VRF e VTEP sejam transportadas sobre o MP-BGP, que assim permitem aos VTEPs aprender informações sobre os hosts (via ARP/ND/DHCP etc.).
O BGP EVPN distribui e fornece essa informação para todos os outros pares BGP-EVPN dentro da rede.
Relembrando o VXLAN
O VXLAN prove uma rede de camada 2 sobreposta (overlay) em uma rede de camada 3 (underlay). Cada rede sobreposta é chamada de segmento VXLAN e é identificada por um ID único de 24 bits chamado VNI – VXLAN Network Identifier ou VXLAN ID.
A identificação de um host vem da combinação do endereço MAC e o VNI. Os hosts situados em VXLANs diferentes não podem comunicar entre si (sem a utilização de um roteador). O pacote original enviado por um host na camada 2 é encapsulado em um cabeçalho VXLAN que inclui o VNI associado ao segmento VXLAN que aquele host pertence.
Os equipamentos que transportam os tuneis VXLAN são chamados de VTEP (VXLAN tunnel endpoints).
Quando um VXLAN VTEP ou tunnel endpoint comunica-se com outros VXLAN VTEP, um túnel VXLAN é estabelecido. Um túnel é meramente um mecanismo de transporte através de uma rede IP.
Todo o processamento VXLAN é executado nos VTEPs. O VTEP de entrada encapsula o tráfego com cabeçalho VXLAN, mais um cabeçalho UDP externo , mais um cabeçalhos IP externo, e então encaminha o tráfego por meio de túneis VXLAN. O VTEP do destino remove o encapsulamento VXLAN e encaminha o tráfego para o destino.
Os dispositivos da rede IP de transporte encaminham o tráfego VXLAN apenas com base no cabeçalho IP externo dos pacotes VXLAN (eles não precisam ter suporte à tecnologia VXLAN).
Um outro ponto importante é que a tecnologia VXLAN supera as limitações de apenas 4 mil domínios de broadcast fornecido por VLANs para até 16 milhões de domínios de broadcast com VNIs. Já para as limitações do Spanning-Tree que coloca os caminhos redundantes em estado de bloqueio, a tecnologia VXLAN permite a construção de todos os uplinks como parte de um backbone IP (rede underlay), utilizando protocolos de roteamento dinâmico para escolha do melhor caminho ao destino, assim fazendo uso do ECMP (Equal Cost Multipath) em uma topologia Spine-Leaf, por exemplo.
BGP EVPN
O BGP EVPN difere do comportamento “Flood and Learn” executado por tuneis VXLANs em diversas maneiras. Enquanto o tráfego multidestination (BUM: broadcast,unicast unknown e multicast) encaminhado pelo VXLAN sem o BGP EVPN necessita de utilizar grupos multicast, o EVPN permite a replicação da identificação dos dispositivos finais com o MP-BGP , assim como as informações do VTEP que ele está associado. As comunicações ARP para IPv4 também pode ser suprimida, aprimorando assim a eficiência do transporte dos dados.
LAB
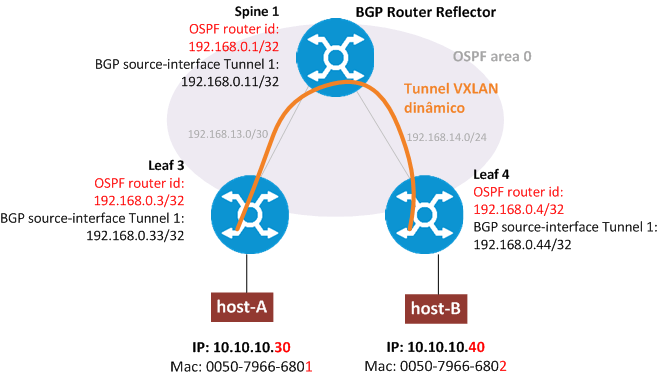
No laboratório abaixo utilizamos os roteadores HP VSR no release R0621P18-X64, no EVE-NG.
Ambos os Spines estão configurados como VTEP e encaminharão o tráfego do VXLAN VNI 10. A instancia criada para esse cliente, chamamos de ‘clientea’.
O Spine está configurado como BGP Router Reflector fechando peerring com ambos Leafs. Nenhum Leaf fecha peering BGP entre si, somente como Spine.
O VRRP (Virtual Router Redundancy Protocol) permite a utilização de um endereço IP virtual em diferentes Switches/Roteadores. O funcionamento do VRRP é bem simples, dois ou mais dispositivos são configurados com o protocolo para troca de mensagens e então, o processo elege um equipamento MASTER e um ou mais como BACKUP.
Em caso de falha do Roteador VRRP Master o Roteador VRRP Backup assumirá rapidamente a função e o processo ocorrerá transparente para os usuários da rede.
Galera, montei um laboratório de VRRP no Simulador HP para o Comware 7 com o objetivo de validar a sintaxe dos comandos, além de testar o protocolo conforme cenário abaixo..
Para aqueles que não conhecem o VRRP, o protocolo funciona para redundância de Gateway em uma rede, com o objetivo de 2 ou mais roteadores compartilharem o mesmo IP virtual no modo ativo/backup ou ativo/ativo. O padrão do protocolo é o ativo(Master)/backup.
Segue a configuração do VRRP nos Roteadores R1 e R2 além da configuração do Switch.
# Switch
vlan 2
#
interface GigabitEthernet1/0/2
port link-mode bridge
port access vlan 2
#
interface GigabitEthernet1/0/3
port link-mode bridge
port access vlan 2
#
Roteador - R1
interface GigabitEthernet 0/0/2
port link-mode route
ip add 192.168.1.2 255.255.255.0
vrrp vrid 1 virtual-ip 192.168.1.1
vrrp vrid 1 priority 110
Roteador - R2
interface GigabitEthernet 0/0/2
port link-mode route
ip add 192.168.1.3 255.255.255.0
vrrp vrid 1 virtual-ip 192.168.1.1
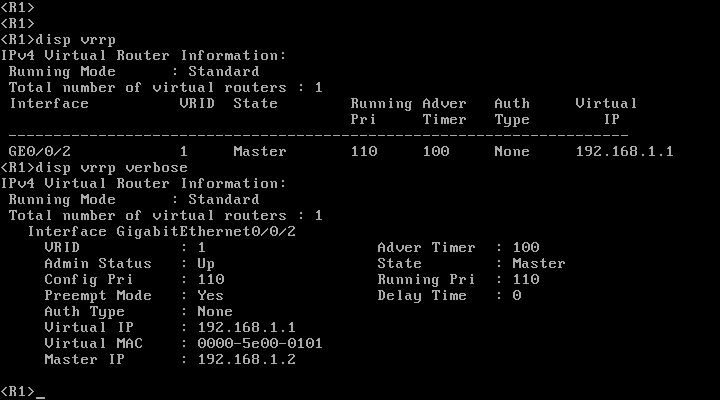
Os comandos display vrrp e display vrrp verbose executados nos roteadores exibem valiosas informações sobre o status do VRRP.
Os comandos são identicos para a versão 5 do Comware.
Uma rota estática flutuante é uma rota estática com uma distância administrativa maior do que a estabelecida por padrão em Switches e Roteadores. Por exemplo, no Comware da HP as rotas estáticas possuem distância administrativa com o valor 60 e o protocolo OSPF com as rotas externas com o valor 150, nesse caso pelo fato da menor distância administrativa ser escolhida quando duas rotas idênticas são aprendidas de maneiras distintas pelo roteador, o equipamento escolherá o processo com menor AD ( administative distance/ distancia administrativa).
Como exemplo, poderíamos imaginar um roteador com 2 links, em um deles a rota 192.168.1.0/24 pode ser aprendida via rotas externas OSPF e nesse caso precisaremos encaminhar o tráfego para esse link como principal. Já como backup configuraríamos a rota estática 192.168.1.0/24 com a distância administrativa com o valor 250 apontando para o next-hop do segundo link.
Quando o primeiro link apresentar problemas, o processo OSPF perceberá a falha e removerá a rota 192.168.1.0/24 aprendida dinamicamente e começará a utilizar a rota estática (não utilizada anteriormente) com o mesmo endereço 192.168.1.0/24 configurada para encaminhar os pacotes para o segundo link.
Quando o OSPF voltar a funcionar com o restabelecimento do primeiro link, a rota estática deixará de ser utilizada, voltando para o encaminhamento de pacotes pela rota aprendida dinamicamente.
[Comware] ip route-static 192.168.1.0 255.255.255.0 172.17.1.2 preference 250
Obs: Lembre-se que a rota estática só entrará na tabela de roteamento se a interface correspondente ao próximo salto (next-hop) estiver UP.
Caso tenham alguma dúvida sobre o assunto, deixem um comentário.