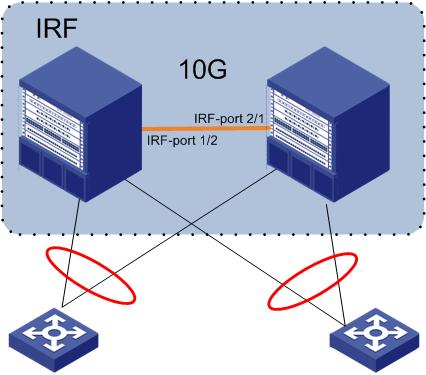
O protocolo IRF v2 permite o “empilhamento” de Switches modulares e empilháveis (stackable), trazendo inúmeras vantagens como redundância, facilidade no gerenciamento, etc.
O IRF pode trazer problemas quando há a quebra do Link 10G que mantém o IRF ativo, essa quebra é chamada de SPLIT. Quando um equipamento percebe que o Master não está respondendo ele assume as suas funções, e nesse caso, com os 2 equipamentos funcionando, ocorrerá a duplicação de alguns serviços e trazendo diversos conflitos na Rede(lembrando que apenas a fibra que sincroniza as informações para o IRF foi danificada).
Publicamos alguns posts no blog com a configuração de proteção para que os equipamentos percebam quando ocorre um SPLIT e bloqueiem um dos equipamentos colocando-o em estado de Recovery, deixando todas as portas inutilizáveis.
É possível utilizar features como BFP e o LACP para monitoração do IRF v2 e escolher algumas interfaces mais críticas para continuarem encaminhando no caso de falha no cabo que conecta o IRF.
Um detalhe importante a ser percebido é que após a correção do SPLIT (com reparo do cabo 10G danificado) o Switch que estava em estado de Recovery reiniciará automaticamente para efetuar o merge (junção) novamente no IRF. Segue abaixo as saídas após a quebra do IRF
[Switch]
#May 29 04:12:18:253 2000 Switch IFNET/4/INTERFACE UPDOWN:
Trap 1.3.6.1.6.3.1.1.5.3: Interface 11796529 is Down,
ifAdminStatus is 1, ifOperStatus is 2
%May 29 04:12:18:254 2000 Switch IFNET/3/LINK_UPDOWN:
Ten-GigabitEthernet1/0/50 link status is DOWN.
System is busy with VIU configuration recovery, please wait a moment...
[Switch]disp mad verbose
Current MAD status: Recovery
Excluded ports(configurable):
Excluded ports(can not be configured):
Ten-GigabitEthernet1/0/50
MAD ARP disabled.
MAD LACP disabled.
MAD BFD enabled interface:
Vlan-interface10
mad ip address 192.168.1. 1 255.255.255.252 member 1
mad ip address 192.168.1. 2 255.255.255.252 member 2
! Após reconectarmos as portas do IRF o Switch reiniciará automaticamente
%May 29 04:13:55:028 2000 Switch STM/6/STM_LINK_STATUS_UP:
IRF port 2 is up.
O IRF (Intelligent Resilient Framework) é uma tecnologia de virtualização de switches com o sistema Comware que permite interconectar múltiplos switches físicos, transformando-os em um único switch lógico.
Uma das coisas bacanas da utilização do IRF é a possibilidade de transformarmos diversos Switches físicos em um único Switch lógico facilitando o modo de gerenciamento. Todos os equipamentos serão visualizados como uma única “caixa”. Na versão 2 do protocolo é possível efetuar o Stacking utilizando links de 10G.
O “split brain” é um problema crítico que pode ocorrer em tecnologias de clusterização ou virtualização de dispositivos, como o IRF (Intelligent Resilient Framework) em switches Comware e ocorre quando a comunicação entre os membros do cluster é interrompida, fazendo com que cada parte do cluster passe a operar como um sistema independente, acreditando ser o único ativo. No contexto do IRF, isso significa que cada conjunto de switches isolados passa a se comportar como um switch lógico separado.
Para prevenir o split brain, o IRF utiliza o mecanismo MAD (Multi-Active Detection). O MAD monitora a conectividade entre os membros do IRF e toma medidas para evitar problemas em caso de falha na comunicação.
Como o LACP se integra ao MAD?
O LACP pode ser usado como um método de detecção MAD, oferecendo uma camada extra de proteção. A ideia principal é usar os pacotes LACP trocados entre os switches do IRF e um switch intermediário (ou outro dispositivo de rede) para monitorar a integridade da conexão.
Uma das features que podem ser utilizadas nesse cenário é a utilização de Link Aggregation distribuído (Ditribuited Link Aggregation) entre os equipamentos do IRF com Switches de acesso (sem configuração adicional no Link Aggregation).
Se um Switch empilhado apresentar algum problema, como por exemplo, problemas elétricos, o(s) outro(s) Switches serão capazes de permitir a continuidade do encaminhamento em Camada 2 e 3 (incluindo processos de Roteamento Dinâmico).
Porém, um dos problemas que o IRF pode trazer é quando ocorre uma quebra do Link 10G que mantém o IRF ativo, chamado de SPLIT. Cada caixa ira agir como se fosse o MASTER do IRF, duplicando alguns serviços e trazendo diversos conflitos na Rede.
O MAD é uma das formas para os Switches do Stack detectarem que houve o SPLIT no IRF colocando o Equipamento com o maior Member ID do IRF (não Master) em modo Recovery, bloqueando assim todas as suas portas.
Após restaurado o Link do IRF as portas serão vinculadas novamente o Stack e ao seu estado normal de encaminhamento.
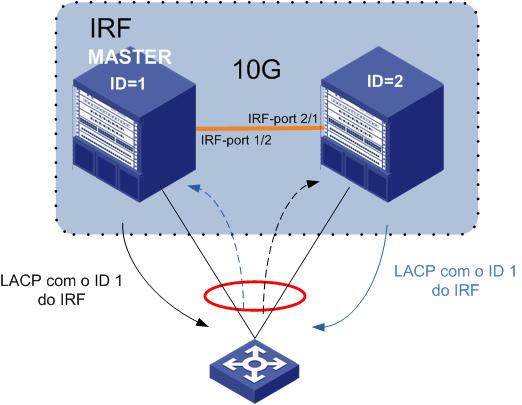
Uma das formas utilizadas pelo MAD para detecção de falha é utilizando uma extensão do protocolo LACP ( Link Aggregation). No TLV do protocolo é inserido o ID do Switch membro do IRF. Nesse caso os Switches da outra ponta do Link Aggregation, encaminham de forma transparente os LACP’s para os Switches Membros do IRF.
Como no exemplo acima, se não há SPLIT no IRF, todas mensagens serão geradas pelo ID do MASTER.
Em caso de quebra do SPLIT as mensagens serão geradas com o ID de cada equipamento e nesse caso o bloqueio das portas do não-Master.
Após detecção as portas bloqueadas do IRF pelo LACP com MAD.
Configuração
A configuração abaixo deverá ser aplicada somente no Switch com o IRF versão 2 “já ativo”.
[S7500]interface bridge-aggregation 1
!Criando a Interface Bridge-Aggregation 1
[S7500-Bridge-Aggregation1] link-aggregation mode dynamic
! Ativando a troca do protocol LACP no Link Aggregation
[S7500-Bridge-Aggregation1] mad enable
! Ativando a extensão MAD no protocol LACP
[S7500-Bridge-Aggregation1] quit
[S7500] interface gigabitethernet 1/3/0/2
[S7500-GigabitEthernet1/3/0/2] port link-aggregation group 1
!Adicionando a interface ao Link Aggregation 1
[S7500-GigabitEthernet1/3/0/2] quit
[S7500] interface gigabitethernet 2/3/0/2
[S7500-GigabitEthernet2/3/0/2] port link-aggregation group 1
!Adicionando a interface ao Link Aggregation 1
[S7500-GigabitEthernet2/3/0/2] quit
Obs: Os switches de acesso conectados ao IRF pelo Link Aggregation não necessitam da configuração do MAD. Mas o fabricante sugere que esse Switch seja um equipamento H3C.
“Requires an intermediate switch, which must be an H3C switch that supports the extended LACP.”
Comandos Display
S7500] display mad
MAD LACP enabled.
Comando display após SPLIT do IRF no Switch não Master
[S7500]display mad verbose
Current MAD status: Recovery
! Switch não-Master em modo recovery após perceber o SPLIT no IRF
! (bloqueando todas as portas)
…………………………
MAD enabled aggregation port:
Bridge-Aggregation1
Obs: o modo Recovery também permite excluímos algumas portas para que continuem em estado de encaminhamento. Há também um segundo modo de utilizar o MAD para detecção de SPLIT utilizando o Protocolo BFD.
O protocolo IRF v2 permite o “empilhamento” de Switches modulares e empilháveis, trazendo inúmeras vantagens como redundância, facilidade no gerenciamento, etc.
Como citado em outros posts, um dos problemas que o IRF pode trazer ocorre quando há uma quebra do Link 10G que mantém o IRF ativo, chamado de SPLIT. Cada caixa ira agir como se fosse o MASTER do IRF, duplicando alguns serviços e trazendo diversos conflitos na Rede.
O “split brain” é um problema crítico que pode ocorrer em tecnologias de clusterização ou virtualização de dispositivos, como o IRF (Intelligent Resilient Framework) em switches Comware. Ele ocorre quando a comunicação entre os membros do cluster é interrompida, fazendo com que cada parte do cluster passe a operar como um sistema independente, acreditando ser o único ativo. No contexto do IRF, isso significa que cada conjunto de switches isolados passa a se comportar como um switch lógico separado.
Imagine um IRF com quatro switches. Se o link que conecta esses switches for interrompido no meio, o IRF se divide em dois grupos de dois switches. Cada grupo agora opera independentemente, com seus próprios endereços MAC, endereços IP de gerenciamento e tabelas de roteamento. Isso leva a sérios problemas na rede:
Duplicação de endereços IP e MAC: Cada parte do IRF agora pode ter o mesmo endereço IP de gerenciamento e os mesmos endereços MAC virtuais, causando conflitos na rede e tornando a comunicação imprevisível.
Loop de Camada 2: Se houver caminhos redundantes na rede que conectam as duas partes divididas, loops de Camada 2 podem se formar, causando tempestades de broadcast e paralisando a rede.
Inconsistências de roteamento: Cada parte do IRF terá suas próprias tabelas de roteamento, levando a decisões de roteamento incorretas e pacotes sendo enviados para destinos errados.
Perda de conectividade: Dispositivos conectados a diferentes partes do IRF dividido não conseguirão se comunicar entre si.
Causas do Split Brain em IRF:
Falha física nos links de interconexão: Cabos danificados, problemas nas portas dos switches ou falhas em equipamentos intermediários podem interromper a comunicação entre os membros do IRF.
Problemas de software: Bugs no software dos switches ou configurações incorretas podem levar à perda de comunicação entre os membros do IRF.
Sobrecarga da rede: Em casos extremos, uma sobrecarga massiva na rede pode afetar a comunicação entre os switches do IRF.
Mecanismos de Prevenção: MAD (Multi-Active Detection)
O MAD é uma das formas para os Switches do Stack detectarem o SPLIT no IRF colocando o Equipamento com o maior Member ID do IRF (não Master) em modo Recovery, bloqueando assim todas as suas portas.
Uma das técnicas para detecção do SPLIT é com é com a utilização do protocolo BFD, criando uma VLAN somente para gerenciamento do IRF com um IP primário e secundário para comunicação do protocolo e um meio físico para conexão das “caixas” (fibra ou UTP) independente da comunicação do IRF.
Configuração
A configuração abaixo deverá ser aplicada somente no Switch com o IRF versão 2 formado.
#
Vlan 900
#
interface Vlan-interface900
description Monitoracao IRFv2 (MAD + BFD)
mad bfd enable
!Ativando o MAD + BFD
mad ip address 192.168.0.1 255.255.255.252 member 1
! Configurando o IP do Switch “1”
mad ip address 192.168.0.2 255.255.255.252 member 2
! Configurando o IP do Switch “2”
#
Obs: cada Switch deverá ter uma porta na VLAN 900 para comunicação do BFD.
As interfaces não participarão do STP.
Comandos Display
[S7500] display mad
MAD LACP enabled.
Comando display após SPLIT do IRF no Switch não Master
[S7500]display mad verbose
Current MAD status: Detect
! Em caso de SPLIT o Switch não-Master exibiria o status como Recovery
Excluded ports(configurable):
Excluded ports(cannot be configured):
Ten-GigabitEthernet1/8/0/1
Ten-GigabitEthernet1/9/0/2
Ten-GigabitEthernet2/8/0/1
Ten-GigabitEthernet2/9/0/2
MAD LACP disabled.
MAD BFD enabled interface:
Vlan-interface900
mad ip address 192.168.0.1 255.255.255.252 member 1
mad ip address 192.168.0.2 255.255.255.252 member 2
Eu já escrevi alguns post sobre a atenção que deve ser dada para a integração entre Switches e Roteadores baseados no Cowmare quando há a necessidade de compartilhar o roteamento dinâmico.
Como no exemplo abaixo, podemos ver que por padrão, toda rota estática é atribuída com o valor 60 para a distância administrativa. De forma didática, faço a comparação nas duas saídas do comando “display ip routing-table” da escolha da tabela de Roteamento pela rota aprendida com a menor distância adminstrativa (no primeiro quadro via rota estática e no segundo exemplo via OSPF).
[Switch] ip route-static 192.168.10.0 255.255.255.0 192.168.12.2 [Switch] [Switch] display ip routing-table Routing Tables: Public Destinations : 5 Routes : 5
Destination/Mask Proto Pre Cost NextHop Interface
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0 127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0 192.168.10.0/24 Static 60 0 192.168.12.2 Eth0/0/0 192.168.12.0/30 Direct 0 0 192.168.12.1 Eth0/0/0 192.168.12.1/32 Direct 0 0 127.0.0.1 InLoop0
Com a rota aprendida dinâmicamente via OSPF (e a estática ainda configurada), percebam que o roteador insere apenas a rota com a menor distância administrativa (valor 10 para o OSPF).
[Switch]display ip routing-table Routing Tables: Public Destinations : 5 Routes : 5
Destination/Mask Proto Pre Cost NextHop Interface
127.0.0.0/8 Direct 0 0 127.0.0.1 InLoop0 127.0.0.1/32 Direct 0 0 127.0.0.1 InLoop0 192.168.10.0/24 OSPF 10 2 192.168.12.2 Eth0/0/0 192.168.12.0/30 Direct 0 0 192.168.12.1 Eth0/0/0 192.168.12.1/32 Direct 0 0 127.0.0.1 InLoop0
Apesar da rota aprendida dinâmicamente “tomar” o lugar da rota estática e possuir o mesmo next-hop (no caso 192.168.12.2, interface Eth0/0/0), em redes mais complexas, o roteamento poderia escolher um caminho menos desejado pelo administrador de rede, visto que em equipamentos de outros fabricantes as rotas estáticas são atribuídas com a distâncias administrativa 1 ( e isso pode passar desapercebido ).
O comando “ip route-static default-preference 1” ajuda aqueles que estão acostumados a trabalhar com ambos roteamento dinâmico e estático, permitindo que as novas rotas configuradas possuam a distância adminstrativa 1 (nesse caso, melhor que todos os protocolos de Roteamento Dinâmico).
[Switch] ip route-static default-preference 1
Caso você prefira escolher manualmente o peso que cada rota terá, basta adicionar o “preference” no final de cada rota.
[Switch] ip route-static 192.168.20.0 255.255.255.0 192.168.12.2 preference ? INTEGER Preference value range
O IRF (Intelligent Resilient Framework) é uma tecnologia de virtualização de switches baseados no Comware que permite interconectar múltiplos switches físicos, transformando-os em um único switch lógico. Todos os equipamentos serão visualizados como uma única “caixa”, aumentando a disponibilidade da rede.
Uma das facilidades da versão 2 é a possibilidade de utilizarmos interfaces 10G para a construção IRF (sem a necessidade de cabos ou módulos específicos ) e possibilidade da utilização de Switches Modulares para construção da topologia.
Em resumo, o IRF simplifica a administração, aumenta a resiliência e a escalabilidade da rede, tratando vários switches como um só. É como se você tivesse um único switch com mais recursos computacionais e alta disponibilidade.
Pontos importantes sobre o IRF:
Conexão física: Os switches são conectados através de portas específicas de alta velocidade, geralmente 10G ou superiores.
Topologia: O IRF suporta diferentes topologias, como anel ou estrela.
Configuração: A configuração do IRF é relativamente simples, envolvendo a definição de um ID para cada switch e a configuração das portas de conexão.
Split Brain: Um problema que pode ocorrer no IRF é o “split brain”, onde a conexão entre os switches é interrompida, fazendo com que cada parte do IRF se comporte como um switch independente, o que pode causar problemas na rede. Mecanismos como o MAD (Multi-Active Detection) ajudam a prevenir esse problema.
Configuração
A configuração do IRF é dividida nos passos abaixo ( utilizaremos[Sw1] e [Sw2] antes dos comandos para diferenciarmos os dispositivos):
1º Converta os 2 Switches no modo IRF
[Sw1]chassis convert mode irf ! Convertendo o Switch 1 no modo IRF
[Sw2]chassis convert mode irf ! Convertendo o Switch 2 no modo IRF
Após a conversão dos Chassis para modo IRF, reinicie os Switches. Os equipamentos subirão com a configuração dos módulos como 1/2/0/1 ( para a porta antes exibida na configuração como 2/0/2; e assim por diante)
2º Renumere o Segundo Switch
[Sw2]irf member 1 renumber 2 ! Forçaremos as portas do Switch 2 para exibirem no formato 2/2/0/x
Reinicie o Switch
3º Altere a prioridade do Switch Master
[Sw1]irf member 1 priority 32 ! O Switch com maior prioridade será eleito o Master ( por default a prioridade de todos os Switches será 1)
4º Deixe as portas 10G que participarão do IRF em shutdown.
[Sw1] interface Ten-GigabitEthernet1/3/0/2 [Sw1-Ten-GigabitEthernet1/3/0/2] shutdown ! Configurando a porta 10G 1/3/0/1 do Switch 1 em shutdown
[Sw2] interface Ten-GigabitEthernet2/3/0/2 [Sw2-Ten-GigabitEthernet2/3/0/2] shutdown ! Configurando a porta 10G 2/3/0/1 do Switch 2 em shutdown
5º Crie a interface lógica para o IRF
[Sw1] irf-port 1/2 ! Criando a interface lógica IRF 1/2 [Sw1-irf-port 1/2] port group interface Ten-GigabitEthernet1/3/0/2 mode enhanced ! Adicionando a porta 10G 1/3/0/2 do Switch 1 na interface IRF no modo enhanced
[Sw2] irf-port 2/1 ! Criando a interface lógica IRF 2/1 [Sw2-irf-port 2/1] port group interface Ten-GigabitEthernet2/3/0/2 mode enhanced ! Adicionando a porta 10G 2/3/0/2 do Switch 1 na interface IRF no modo enhanced
Obs: O fabricante sugere a configuração das portas IRF em modo cruzado, como por exemplo, a porta IRF 1/2 do Switch 1 conectado na porta IRF 2/1 do Switch 2
Após removermos a porta do Switch 2 participante do IRF do shutdown, será exibida a seguinte mensagem:
IRF merge occurs and the IRF system needs a reboot.
Salve a configuração dos 2 Switches e reinicie o Segundo Switch ( o dispositivo não-Master). Espere os módulos subirem e os Switches tornarem-se um só! Display
Para verificar o IRF podemos utilizar os comandos abaixo
[SW1]display irf configuration
MemberID NewID IRF-Port1 IRF-Port2
1 1 disable Ten-GigabitEthernet1/3/0/2
2 2 Ten-GigabitEthernet2/3/0/2 disable
[SW1]display irf topology
Topology Info
---------------------------------------
IRF-Port1 IRF-Port2
Switch Link neighbor Link neighbor Belong To
1 DIS -- UP 2 00e0-fc0a-15e0
2 UP 1 DIS -- 00e0-fc0a-15e0
Diferente da agregação de links com Brige-Aggregation (Link Aggregation ou EtherChannel), que opera na camada 2 (enlace de dados), o Route-Aggregation atua na camada 3 (rede). Ela permite combinar múltiplas interfaces físicas em uma única interface lógica, configurar endereço IP, limitar o dominio de broadcast na interface, aumentar a capacidade de transmissão e fornecer redundância em interfaces no modo routed.
Conceitos Chave:
Interface Route Aggregation: A interface virtual que representa o conjunto de interfaces físicas agregadas.
Interfaces Membro: As interfaces físicas que compõem o grupo de agregação.
Modos de Operação: Algoritmos que determinam como o tráfego é distribuído entre as interfaces membro.
Como Configurar Agregação de Rotas no Comware:
A configuração envolve os seguintes passos:
Crie a Interface Route Aggregation:
[Sysname] interface Route-Aggregation <número>
Substitua <número> por um identificador único para a interface.
Escolha o Modo de Operação (Recomendado):
hash: Distribui o tráfego usando um hash dos endereços IP de origem e destino, oferecendo um bom balanceamento de carga na maioria dos casos.
load-share: Distribui o tráfego de forma mais uniforme, independentemente dos endereços IP.
Diferenças entre Bridge Aggregation e Route Aggregation:
Característica
Bridge Aggregation
Route Aggregation
Camada de Operação
Camada 2
Camada 3
Tipo de Tráfego
Ethernet
IP
Endereçamento
Não necessário nas interfaces membro
Necessário na interface Route Aggregation
Função Principal
Largura de banda e redundância entre switches
Largura de banda e redundância entre roteadores
Observações Importantes:
As interfaces membro devem ter a mesma velocidade e configuração duplex.
A configuração deve ser consistente em ambos os lados da conexão.
Consulte a documentação específica do seu equipamento Comware para detalhes adicionais e configurações avançadas. Implementar a agregação de rotas pode melhorar significativamente o desempenho e a resiliência da sua rede.
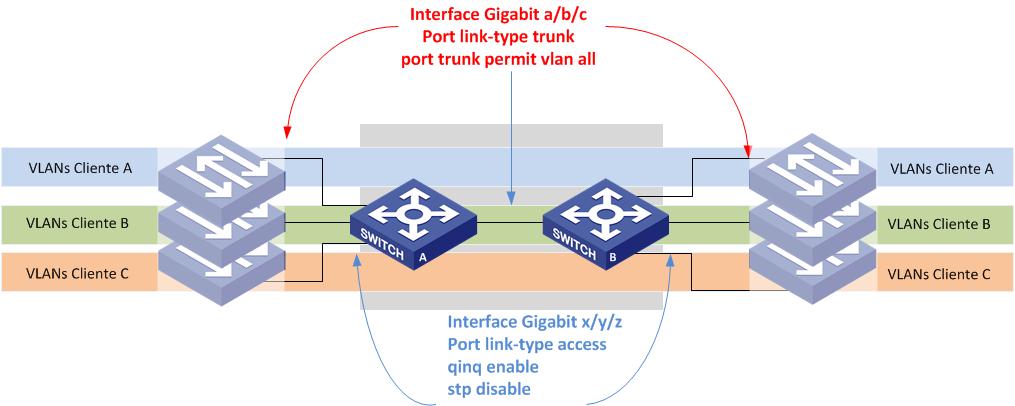
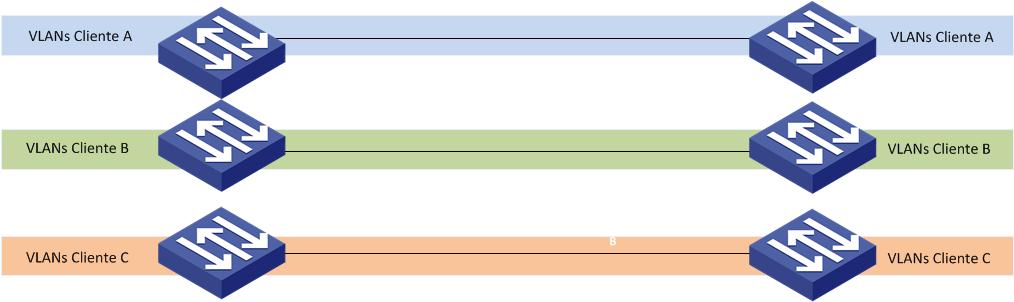
A feature QinQ (802.1q sobre 802.1q), conhecido também como Stacked VLAN ou VLAN sobre VLAN, suporta a utilização de duas TAGs 802.1q no mesmo frame para trafegar uma VLAN dentro de outra VLAN – sem alterar a TAG original.
Para o cliente é como se a operadora tivesse estendido o cabo entre os seus Switches. Já para a Operadora não importa se o cliente está mandando um frame com TAG ou sem TAG, pois ele adicionará mais uma TAG ao cabeçalho e removerá na outra ponta apenas a ultima TAG inserida.
Em resumo, o tráfego no sentido de entrada na porta configurada com QinQ, adicionará uma TAG 802.1q ao quadro, mesmo em casos que já houver a marcação de VLANs, entretanto no sentido de saída, é removido apenas a última TAG acrescentada, sendo mantida a TAG 802.q inserida pelo cliente.
Um switch conecta a rede do cliente (com VLANs 10 e 20) à rede do provedor usando a S-VLAN 100:
<Sysname> system-view
[Sysname] interface GigabitEthernet1/0/1
[Sysname-GigabitEthernet1/0/1] qinq enable
[Sysname-GigabitEthernet1/0/1] port vlan 100
Neste exemplo, todos os frames que entram na interface GigabitEthernet1/0/1 receberão a tag S-VLAN 100.
Exemplo de Configuração de QinQ Seletivo:
Mapear a C-VLAN 10 para a S-VLAN 100 e a C-VLAN 20 para a S-VLAN 200:
<Sysname> system-view
[Sysname] vlan mapping 10 to 100
[Sysname] vlan mapping 20 to 200
[Sysname] interface GigabitEthernet1/0/1
[Sysname-GigabitEthernet1/0/1] qinq selective
[Sysname-GigabitEthernet1/0/1] port link-type hybrid
[Sysname-GigabitEthernet1/0/1] undo port hybrid vlan 100
[Sysname-GigabitEthernet1/0/1] port hybrid tagged-vlan 100
[Sysname-GigabitEthernet1/0/1] undo port hybrid vlan 200
[Sysname-GigabitEthernet1/0/1] port hybrid tagged-vlan 200
Verificação:
display interface <tipo-de-interface> <número-da-interface>: Exibe informações sobre a interface, incluindo a configuração de QinQ.
Capturas de pacotes (usando um analisador de protocolo como o Wireshark) podem ser usadas para verificar as tags VLAN nos frames.
Considerações Importantes:
MTU (Maximum Transmission Unit): O QinQ adiciona bytes extras ao frame, o que pode exigir o ajuste do MTU nas interfaces envolvidas para evitar fragmentação. Geralmente, aumenta-se o MTU para 1504 ou 1508 bytes. O comando é: [Sysname-GigabitEthernet1/0/1] mtu 1504.
Interoperabilidade: Certifique-se de que os switches em ambas as extremidades da conexão QinQ sejam compatíveis e estejam configurados corretamente.
Configurando
No Exemplo acima deveremos configurar nos Switches A e B uma VLAN para cada cliente e a configurar as interfaces conectadas aos Switches do cliente, como qinq enable. Como detalhe, percebam que é necessário desabilitar o STP em cada interface para os BPDU’s de cada empresa não interferir na topologia STP de cada uma. Segue abaixo a configuração dos Switches A e B:
Vlan 10
name clienteA
!
Vlan 11
name clienteB
!
Vlan 12
name clienteC
!
Interface GigabitEthernet x/y/z
port link-type access
qinq enable
stp disable
Em caso de necessidade de transporte de protocolos de camada 2 como CDP, LLDP, STP e etc, é possivel utilizar na interface algum dos comandos abaixo:
A configuração dos Switches de cada cliente não sofre nenhuma alteração em particular e a visão de cada um será como se os Switches estivessem diretamente conectados.
A funcionalidade uRPF (Unicast Reverse Path Forwarding) protege a rede contra ataques do tipo spoofing. A técnica de spoofing é utilizada por atacantes que falsificam o endereço IP de origem do pacote para os mais diversos fins.
O uRPF pode impedir esses ataques de spoofing com o endereço de origem. Ele verifica se a interface que recebeu um pacote é a interface de saída na FIB, que corresponde ao endereço de origem do pacote. Caso contrário, a uRPF considera um ataque de falsificação e descarta o pacote.
Lembrando que por padrão, para o encaminhamento de pacotes, o roteador valida apenas o endereço de destino de um pacote IP.
Exemplo
Em um exemplo simples, é como se um roteador com uma interface com o endereço de LAN 192.168.1.0/24 receber um pacote com o endereço de origem 172.16.1.20. Esse endereço não faz parte da rede local.
Modos uRPF
O uRPF possui 2 modos distintos (strict e loose) que podem potencialmente ajudar a reduzir ataques com endereços IP falsificados.
Strict uRPF – Para passar a verificação estrita do uRPF, o endereço de origem de um pacote deve ser correspondente ao endereço de destino da interface de saída da FIB. Em alguns cenários (por exemplo, roteamento assimétrico), o Strict uRPF estrito pode descartar pacotes válidos. O Strict uRPF estrito é frequentemente implantado entre um PE e um CE.
[R2-GigabitEthernet1/0] ip urpf strict
Loose uRPF – Para passar a verificação Loose uRPF, o endereço de origem de um pacote deve corresponder o endereço de destino de uma entrada qualquer da FIB. O Loose uRPF pode evitar descartar pacotes válidos, mas pode deixar passar pacotes de um atacante. O Loose uRPF é frequentemente implementado entre ISPs, especialmente em roteamento assimétrico.
[R2-GigabitEthernet1/0] ip urpf loose
Rota Default
Caso o endereço seja apenas conhecido via rota default, o uRPF continuará bloqueando os endereços. Para permitir os endereços a partir da rota default use o comando “allow-default-route” após a configuração do modo strict ou do loose:
A utilização de VRFs (Virtual Routing and Forwarding) em Roteadores permite a criação de tabelas de roteamentos virtuais que trabalham de forma independente da tabela de roteamento “normal”, protegendo os processos de roteamento de cada cliente de forma individual.
Empresas que prestam serviços de gerenciamento de rede ou monitoração, empresas que vendem serviços em Data Center e provedores de serviço utilizam largamente VRFs, otimizando assim a administração e o retorno financeiro no total do custo de um projeto.
Já o Roteamento entre VRFs ocorre quando há a necessidade de comunicarmos diferentes tabelas de roteamento que estão segregadas por VRF, para compartilharem alguns ou todos os prefixos. Há diversas formas de configurarmos o roteamento entre VRFs, como por exemplo com a utilização de um cabo virado para o próprio roteador com as portas em diferente VRFs [apontando assim uma rota para nexthop da proxima VRF; ou com algum IGP] e também com a utilização de um outro roteador, etc; nesse post explicaremos o roteamento interVRF com o processo MPBGP que é a maneira mais escalável… preparados? Então vamos lá…
Habilitando o import e export das VRFs
Ao configurarmos o processo de roteamento entre VRFs em um mesmo roteador , dois valores de extrema importancia devem ser configurados na VRF: o RD (route distinguisher) e o RT (route target)
RD – Route Distinguisher
Como explicado anteriormente, as VRFs permitem a reutilização de endereços IP em diferentes tabelas de roteamento. Por exemplo, suponha que você tenha que conectar a três diferentes clientes , os quais estão usando 192.168.1.0/24 em sua rede local. Podemos designar a cada cliente a sua própria VRF de modo que as redes sobrepostas são mantidas isoladas em suas VRFs .
O RD funciona mantendo o controle de quais rotas 192.168.1.0/24 pertencem a cada cliente como um diferenciador de rota (RD) para cada VRF. O route distinguisher é um número único adiciondo para cada rota dentro de uma VRF para identificá-lo como pertencente a essa VRF ou cliente particular. O valor do RD é carregado juntamente com uma rota através do processo MP- BGP quando o roteador troca rotas VPN com outros Roteadores PE.
O valor RD é de 64 bits e é sugerido a configuração do valor do RD como ASN::nn ou endereçoIP:nn. Mas apesar das sugestões, o valor é apenas representativo.
[R1-vpn-instance-Cliente_A]route-distinguisher ?
STRING ASN:nn or IP_address:nn VPN Route Distinguisher
!
! Configurando a VRF para os clientes A B e C
ip vpn-instance Cliente_A
route-distinguisher 65000:1
!
ip vpn-instance Cliente_B
route-distinguisher 65000:2
!
ip vpn-instance Cliente_C
route-distinguisher 65000:3
Quando rotas VPN são anunciados entre os roteadores PE via MP-BGP, o RD é incluído como parte da rota, juntamente com o prefixo IP. Por exemplo, uma via para 192.0.2.0/24 na VRF Cliente_B é anunciado como 65000:2:192.0.1.0 / 24.
RT – Route-Target ou VPN-target
Considerando que o valor do RD é utilizado para manter a exclusividade entre rotas idênticas em diferentes VRFs, o RT (route target)é utilizado para compartilhar rotas entre eles. Podemos aplicar o RT para uma VRF com o objetivo de controlar a importação e exportação de rotas entre ela e outras VRFs.
O route target assume a forma de uma comunidade BGP estendida com uma estrutura semelhante à de um RD (que é, provavelmente, porque os dois são tão facilmente confundidos).
Segue abaixo um exemplo de configuração, onde o Cliente_A fará o roteamento entre VRFs com o Cliente_B, já o Cliente_C continuará com a sua VRF isolada dos outros clientes.