O Ethernet Virtual Private Network (EVPN) é uma tecnologia VPN de Camada 2 VPN que fornece conectividade entre dispositivos tanto em Camada 2 como para Camada 3 através de uma rede IP. A tecnologia EVPN utiliza o MP-BGP como plano de controle (control plane) e o VXLAN como plano de dados/encaminhamento (data plane) de um switch/roteador. A tecnologia é geralmente utilizada em data centers em ambiente multitenant ( com múltiplos clientes e serviços) com grande tráfego leste-oeste.
A configuração do EVPN permite ao MP-BGP automatizar a descoberta de VTEPs, assim como o estabelecimento de tuneis VXLAN de forma dinâmica, a utilização de IRB (Integrated Routing and Bridging) anuncia tanto as informações de Camada 2 e 3 para acesso ao host, fornecendo a utilização do melhor caminho através do ECMP e minimizando flood do trafego multidestination (BUM: broadcast,unicast unknown e multicast) .
Em resumo o EVPN possui um address Family que permite que as informações de MAC, IP, VRF e VTEP sejam transportadas sobre o MP-BGP, que assim permitem aos VTEPs aprender informações sobre os hosts (via ARP/ND/DHCP etc.).
O BGP EVPN distribui e fornece essa informação para todos os outros pares BGP-EVPN dentro da rede.
Relembrando o VXLAN
O VXLAN prove uma rede de camada 2 sobreposta (overlay) em uma rede de camada 3 (underlay). Cada rede sobreposta é chamada de segmento VXLAN e é identificada por um ID único de 24 bits chamado VNI – VXLAN Network Identifier ou VXLAN ID.
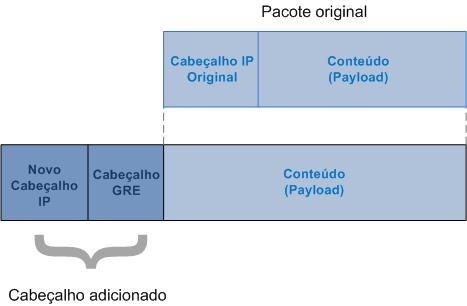
A identificação de um host vem da combinação do endereço MAC e o VNI. Os hosts situados em VXLANs diferentes não podem comunicar entre si (sem a utilização de um roteador). O pacote original enviado por um host na camada 2 é encapsulado em um cabeçalho VXLAN que inclui o VNI associado ao segmento VXLAN que aquele host pertence.
Os equipamentos que transportam os tuneis VXLAN são chamados de VTEP (VXLAN tunnel endpoints).
Quando um VXLAN VTEP ou tunnel endpoint comunica-se com outros VXLAN VTEP, um túnel VXLAN é estabelecido. Um túnel é meramente um mecanismo de transporte através de uma rede IP.
Todo o processamento VXLAN é executado nos VTEPs. O VTEP de entrada encapsula o tráfego com cabeçalho VXLAN, mais um cabeçalho UDP externo , mais um cabeçalhos IP externo, e então encaminha o tráfego por meio de túneis VXLAN. O VTEP do destino remove o encapsulamento VXLAN e encaminha o tráfego para o destino.
Os dispositivos da rede IP de transporte encaminham o tráfego VXLAN apenas com base no cabeçalho IP externo dos pacotes VXLAN (eles não precisam ter suporte à tecnologia VXLAN).
Um outro ponto importante é que a tecnologia VXLAN supera as limitações de apenas 4 mil domínios de broadcast fornecido por VLANs para até 16 milhões de domínios de broadcast com VNIs. Já para as limitações do Spanning-Tree que coloca os caminhos redundantes em estado de bloqueio, a tecnologia VXLAN permite a construção de todos os uplinks como parte de um backbone IP (rede underlay), utilizando protocolos de roteamento dinâmico para escolha do melhor caminho ao destino, assim fazendo uso do ECMP (Equal Cost Multipath) em uma topologia Spine-Leaf, por exemplo.
BGP EVPN
O BGP EVPN difere do comportamento “Flood and Learn” executado por tuneis VXLANs em diversas maneiras. Enquanto o tráfego multidestination (BUM: broadcast,unicast unknown e multicast) encaminhado pelo VXLAN sem o BGP EVPN necessita de utilizar grupos multicast, o EVPN permite a replicação da identificação dos dispositivos finais com o MP-BGP , assim como as informações do VTEP que ele está associado. As comunicações ARP para IPv4 também pode ser suprimida, aprimorando assim a eficiência do transporte dos dados.
LAB
No laboratório abaixo utilizamos os roteadores HP VSR no release R0621P18-X64, no EVE-NG.
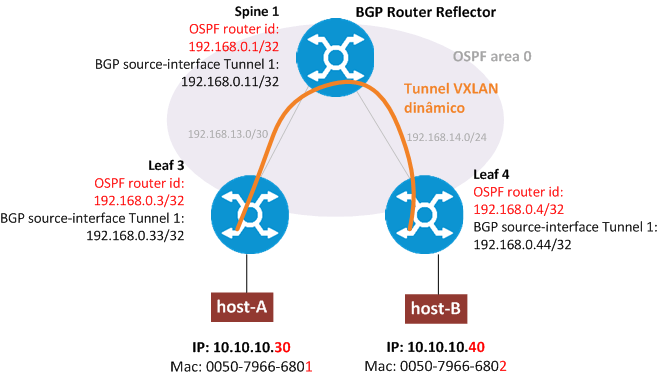
Ambos os Spines estão configurados como VTEP e encaminharão o tráfego do VXLAN VNI 10. A instancia criada para esse cliente, chamamos de ‘clientea’.
O Spine está configurado como BGP Router Reflector fechando peerring com ambos Leafs. Nenhum Leaf fecha peering BGP entre si, somente como Spine.
Configuração SPINE 1
#
sysname Spine-01
#
interface LoopBack0
description OSPF_UNDERLAY
ip address 192.168.0.1 255.255.255.255
#
interface LoopBack1
description BGP_EVPN_UNDERLAY
ip address 192.168.0.11 255.255.255.255
#
interface GigabitEthernet1/0
description CONEXAO_LEAF3
ip address 192.168.13.1 255.255.255.0
#
interface GigabitEthernet2/0
description CONEXAO_LEAF4
ip address 192.168.14.1 255.255.255.0
#
ospf 1 router-id 192.168.0.1
description UNDERLAY_OSPF
area 0.0.0.0
network 192.168.0.1 0.0.0.0
network 192.168.0.11 0.0.0.0
network 192.168.14.0 0.0.0.255
network 192.168.13.0 0.0.0.255
#
bgp 65001
group evpn internal
peer evpn connect-interface LoopBack1
peer 192.168.0.33 group evpn
peer 192.168.0.44 group evpn
#
address-family l2vpn evpn
undo policy vpn-target
peer evpn enable
peer evpn reflect-client
#
Configuração LEAF 3
#
sysname Leaf-03
#
interface LoopBack0
description OSPF_UNDERLAY
ip address 192.168.0.3 255.255.255.255
#
interface LoopBack1
description BGP_EVPN_UNDERLAY
ip address 192.168.0.33 255.255.255.255
#
interface GigabitEthernet1/0
description CONEXAO_SPINE1
ip address 192.168.13.3 255.255.255.0
ospf network-type p2p
#
ospf 1 router-id 192.168.0.3
description UNDERLAY_OSPF
area 0.0.0.0
network 192.168.0.3 0.0.0.0
network 192.168.0.33 0.0.0.0
network 192.168.13.0 0.0.0.255
#
bgp 65001
peer 192.168.0.11 as-number 65001
peer 192.168.0.11 connect-interface LoopBack1
#
address-family l2vpn evpn
peer 192.168.0.11 enable
#
vxlan tunnel mac-learning disable
#
l2vpn enable
#
vsi clientea
arp suppression enable
vxlan 10
evpn encapsulation vxlan
route-distinguisher auto
vpn-target auto export-extcommunity
vpn-target auto import-extcommunity
quit
#
interface GigabitEthernet3/0
xconnect vsi clientea
#
Configuração LEAF 4
#
sysname Leaf-04
#
interface LoopBack0
description OSPF_UNDERLAY
ip address 192.168.0.4 255.255.255.255
#
interface LoopBack1
description BGP_EVPN_UNDERLAY
ip address 192.168.0.44 255.255.255.255
#
interface GigabitEthernet2/0
description CONEXAO_SPINE2
ip address 192.168.14.4 255.255.255.0
ospf network-type p2p
#
ospf 1 router-id 192.168.0.4
area 0.0.0.0
network 192.168.0.4 0.0.0.0
network 192.168.0.44 0.0.0.0
network 192.168.14.0 0.0.0.255
#
bgp 65001
peer 192.168.0.11 as-number 65001
peer 192.168.0.11 connect-interface LoopBack1
#
address-family l2vpn evpn
peer 192.168.0.11 enable
#
vxlan tunnel mac-learning disable
#
l2vpn enable
#
vsi clientea
arp suppression enable
evpn encapsulation vxlan
route-distinguisher auto
vpn-target auto export-extcommunity
vpn-target auto import-extcommunity
quit
vxlan 10
quit
#
interface GigabitEthernet3/0
xconnect vsi clientea
#
Comandos Display bgp l2vpn evpn
Comando display vxlan tunnel
Referências
R2702-HPE FlexFabric 5940 & 5930 Switch Series EVPN Configuration Guide
KRATTIGER, Lukas; KAPADIA, Shyam; JANSEN, David; Building Data Centers with VXLAN BGP EVPN – A Cisco NX-OS Perspective – 2017 CiscoPress