Para o estabelecimento de uma adjacência no OSPF os Roteadores vizinhos devem se reconhecer para trocarem informações, encaminhando e recebendo mensagens Hello nas Interfaces participantes do OSPF; no endereço de Multicast 224.0.0.5.
Durante estabelecimento da Adjacência, serão trocadas informações dos Roteadores da Rede como a informação da área, prioridade dos Roteadores, etc. Após a sincronizarem as informações, os Roteadores da área terão a mesma visão da Topologia e rodarão o algoritmo SPF para escolha do melhor caminho para chegar ao Destino.
Os Roteadores (já) Adjacentes encaminharão mensagens Hellos ( verificação da disponibilidade), mensagens LSA com as atualizações da rede e mensagens a cada 30 minutos de refresh de cada LSA para certificar que os a tabela OSPF (LSDB) esteja sincronizada.
Durante a falha de um Link, a informação é inundada (flooded) para todos os Roteadores Adjacentes da Área.
Em ambientes Multiacesso como redes Ethernet, os Roteadores OSPF elegem um Roteador Designado (DR) para formar Adjacência e encaminhar os LSA’s somente para ele. O Roteador DR reencaminha os updates recebidos por um vizinho para os outros Roteadores na mesma LAN.
Há também a eleição de um Roteador Desingnado de Backup (BDR) para assumir em caso de falha do DR.
O método de eleição do DR e BDR é bastante efetivo e confiável para estabelecimento de Adjacências e mensagens trocadas para manutenção do OSPF, economizando assim recursos conforme o crescimento da Topologia.

Quando ocorre uma mudança na topologia o Roteador/Switch encaminha uma mensagem em Multicast para o endereço 224.0.0.6 que é destinada a todos Roteadores OSPF DR/BDR.
Após o recebimento do Update, o Roteador DR confirma o recebimento (LSAck) e reencaminha a mensagem para os demais roteadores da rede no endereço de Multicast 224.0.0.5; após o recebimento da atualização todos os roteadores deverão confirmar a mensagem ao Roteador Designado (LSAck), tornando o processo confiável.
Se algum Roteador estiver conectado à outras redes, o processo de flood é repetido!
Obs: O BDR não efetua nenhuma operação enquanto o DR estiver ativo!
Como é feita a eleição do DR e BDR?
Durante o processo de estabelecimento de Adjacência é verificado o campo Priority na troca de mensagens Hello. O Roteador com maior valor é eleito o DR e o Roteador com segundo maior valor é eleito o BDR ( em cada segmento).
O valor default da prioridade de todos os Roteador é 1, no caso de empate, é escolhido o valor do ID do Roteador para desempate. Vence quem tiver o maior valor!

Obs: Se a prioridade for configurada como 0, o dispositivo nunca será um DR ou BDR. Nesse caso ele será classificado com DROther ( não DR e não BDR)
Configurando
O valor da prioridade deverá ser configurado na Interface VLAN ou física (Ethernet, GigabitEthernet, etc) dos Switches/Roteadores com o processo de OSPF ativo:
interface Vlan-interface1 ip address 192.168.0.26 255.255.255.0 ospf dr-priority 3 !Configurando a Prioridade para eleição do DR/BDR com o valor 3
Porém….
A prioridade do DR e do BDR não é preemptiva, isto é, para manter a estabilidade da topologia se um dispositivo for eleito como DR e BDR, o mesmo não perderá esse direito até ocorrer algum problema no link ou no dispositivo eleito.
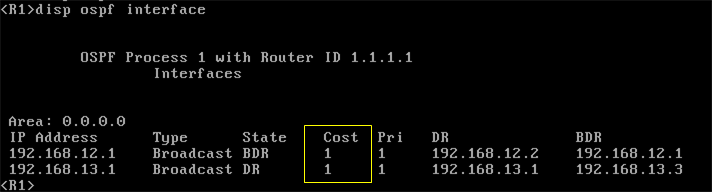
Conforme comando display abaixo em Switches Comware, o Switch configurado com a prioridade 3 perde a eleição (de tornar-se o DR) para dispositivo com a prioridade 4 ( pelo fato de ser inserido na topologia posteriormente a eleição do DR/BR).
[COMWARE]display ospf peer
OSPF Process 100 with Router ID 192.168.0.5
Neighbor Brief Information
Area: 0.0.0.0
Router ID Address Pri Dead-Time Interface State
192.168.0.13 192.168.0.13 0 38 Vlan1 Full/DROther
192.168.0.14 192.168.0.14 1 31 Vlan1 Full/DROther
192.168.0.20 192.168.0.20 1 34 Vlan1 Full/DROther
192.168.0.21 192.168.0.21 4 30 Vlan1 Full/DR
!Roteador DR com a prioridade 4
192.168.0.26 192.168.0.26 5 31 Vlan1 Full/DROther
! Roteador DROther com a prioridade 5 só será o DR na falha do DR e BDR
192.168.0.33 192.168.0.33 1 32 Vlan1 Full/BDR
! Roteador BDR com a prioridade 1
192.168.0.45 192.168.0.45 1 40 Vlan1 Full/DROther
O Switch com a Prioridade 5, irá tornar-se DR somente após falha no DR e no BDR.
Referencias:
Building Scalable Cisco Internetworks – Diane Teare/Catherine Paquet
Duvidas? Deixe um comentário!
Um grande abraço