A IA está transformando a forma como trabalhamos pode impulsionar nossa produtividade quando utilizada de forma eficaz. Nesse vídeo produzido pelo time HPE Networking são abordados os seguintes tópicos:
Aproveitar a IA como consultor e assistente para gerenciar, automatizar e solucionar problemas da sua rede;
Aplicar técnicas de engenharia de prompts para interações mais eficazes com IA;
Usar configurações baseadas em modelos para otimizar a implantação;
Realizar pesquisas rápidas e inteligentes em documentação técnica;
Solucionar problemas de rede simples e complexos com a assistência da IA;
Gerar scripts em Python dinamicamente com IA;
Comunicar-se com a IA por meio de chamadas REST API para automação avançada.
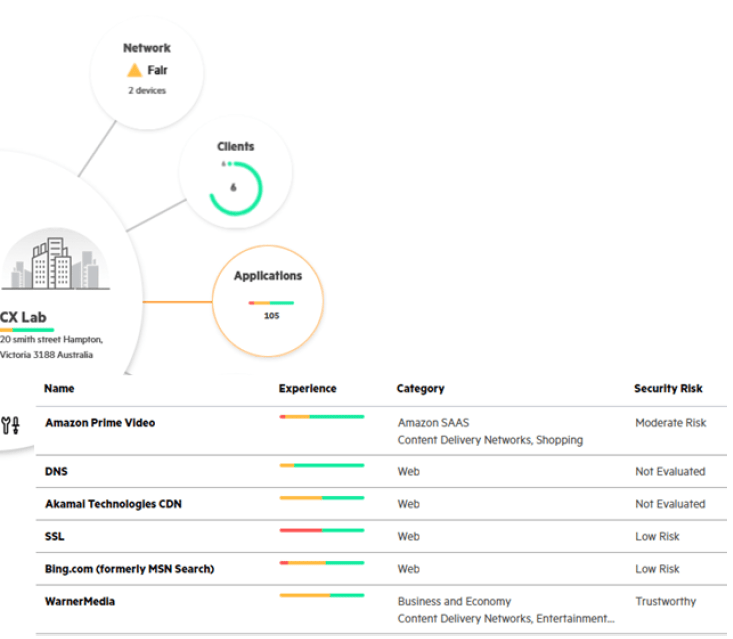
O Application Recognition and Control (ARC) é uma funcionalidade recente nos switches da linha CX, onde os equipamentos realizam Deep Packet Inspection (DPI) do tráfego de usuários.
Essa funcionalidade é especialmente útil para administradores que precisam de políticas avançadas de priorização, bloqueio ou monitoramento de tráfego, garantindo desempenho e segurança em ambientes corporativos.
Com o ARC, é possível analisar padrões de tráfego mesmo em fluxos criptografados, oferecendo importantes para otimização de rede. A integração com o Aruba Central simplifica o gerenciamento, permitindo que as políticas sejam aplicadas de forma centralizada e escalável.
Os benefícios do ARC integrado ao Aruba Central incluem visibilidade completa em camada 7 de mais de 3.700 aplicações e categorias, permitindo a análise detalhada de versões TLS, datas de expiração de certificados e estatísticas de conexão. Além disso, possibilita a aplicação de políticas baseadas em aplicativos, integração com IPFIX para exportar estatísticas de fluxo a coletores externos, e oferece um resumo das principais categorias de aplicativos em uso. O recurso de “time travel” também permite visualizar o tráfego de aplicações em datas e horários específicos, facilitando análises retrospectivas.
Para utilizar o ARC, é necessário validar se o modelo do Switch e o firmware é compativel com a funcionalidade, assim como uma conta no Aruba Central configurada como coletor IPFIX e uma assinatura Foundational ativa (assumindo assume que o switch CX já está adicionado ao Aruba Central, possui uma licença válida e está configurado com conectividade básica, sendo gerenciado totalmente pela plataforma).
Atualmente, esse recurso está disponível nas famílias 6200, 6300 e 6400, permitindo maior controle e visibilidade sobre as aplicações em rede.
A funcionalidade ARC utiliza DPI (Deep Packet Inspection) para identificar aplicações de rede, fornecendo visibilidade e estatísticas detalhadas ao administrador. O mecanismo de DPI opera em cada placa de linha nos switches da série 6400 ou em cada membro do stack nos modelos 6300, analisando os primeiros pacotes de um fluxo TCP/UDP para reconhecer a aplicação. Embora o IPFIX não seja obrigatório para o reconhecimento de aplicações, ele é necessário para reportar estatísticas de fluxo ao administrador. Portanto, o IPFIX deve estar habilitado, pois é responsável por exportar essas informações para um coletor interno ou externo.
O Traffic Insight (TI) atua como um coletor IPFIX interno, monitorando dados recebidos de exportadores de fluxo como o IPFIX. Ele consegue rastrear múltiplas requisições simultaneamente, exibindo os dados na WebUI do switch e disponibilizando essas informações via APIs, que são utilizadas pelo Aruba Central. Vale destacar que o IPFIX é um padrão aberto, compatível com diversos fabricantes de rede, e seu formato é praticamente idêntico ao NetFlow, exceto por alguns campos adicionais.
Antes de iniciar a configuração, é necessário desativar dois recursos: o “IP Source Lockdown” (que previne spoofing de endereço IP por porta) e o “IP Source Lockdown Resource Extended” (que estende dinamicamente os recursos de hardware do IP Source Lockdown). Além disso, para utilizar a visibilidade de aplicações, basta uma assinatura Foundational do Aruba Central nos switches. No entanto, o controle de aplicações (incluindo geração de tags de cliente e criação de políticas) exige uma assinatura Advance.
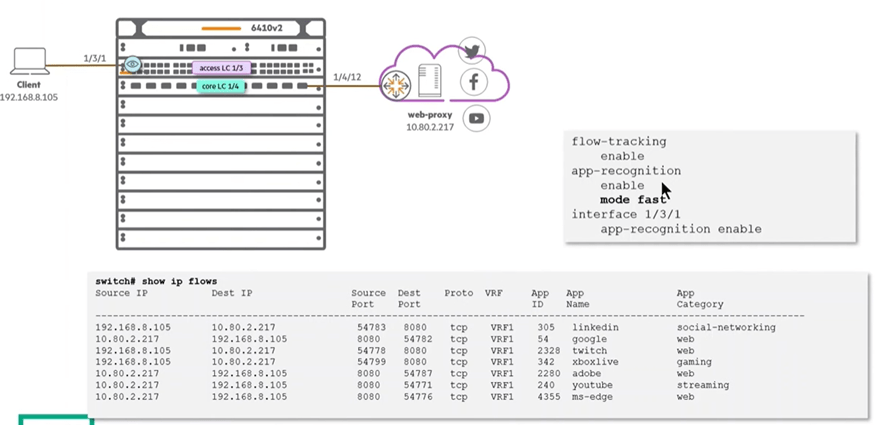
Existem dois modos de operação: o modo padrão (default) e o modo rápido (fast). A principal diferença entre eles está na quantidade de pacotes necessários para identificar as aplicações. Enquanto o modo padrão analisa cerca de 6 pacotes, o modo rápido requer apenas aproximadamente 2 pacotes, permitindo uma identificação 50 milissegundos mais rápida.
É importante observar que, no modo rápido, algumas informações não são capturadas, diferentemente do modo padrão. Isso inclui atributos TLS, códigos de motivo DNS e URLs. Portanto, a escolha entre os modos deve considerar a necessidade entre velocidade de detecção e a profundidade dos dados coletados.
O ARC pode ser habilitado tanto por porta quanto por função (role). Veja abaixo a configuração necessária para ativar o ARC em nível de porta em switches da série 6300. Observação: não é recomendável habilitá-lo em portas de uplink.
Ao utilizar o modo rápido (Fast mode), o sistema identifica o nome da aplicação, sua categoria e descrição, porém com limitações na coleta de metadados.
no ip source-lockdown resource-extended
!
flow-tracking
enable
!
app-recognition
enable
mode fast
!
interface 1/1/4-1/1/5
description clients-ports
no shutdown
no routing
app-recognition enable
exit
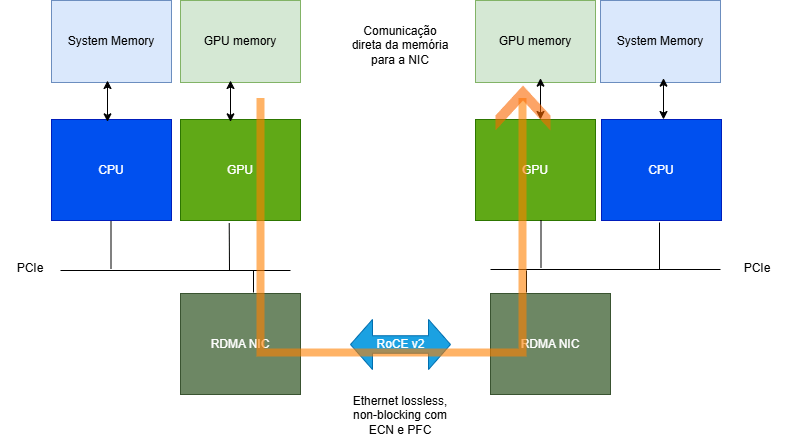
O RDMA, ou Acesso Remoto Direto à Memória, é uma tecnologia que permite que um computador acesse diretamente a memória de outro computador em uma rede, sem envolver o sistema operacional ou a CPU do computador de destino. Pense nisso como uma “conexão direta” entre as memórias de dois sistemas.
O segredo do RDMA está em desviar o caminho tradicional de processamento de dados na rede. Em vez de os dados passarem pela pilha de rede do sistema operacional (que envolve cópias de dados entre o espaço do usuário e o espaço do kernel, interrupções da CPU, etc.), o RDMA permite que a placa de rede (NIC) com capacidade RDMA (também conhecida como RNIC – RDMA NIC) execute a transferência de dados diretamente para a memória do aplicativo no host remoto.
A tecnologia RoCE (RDMA over Converged Ethernet) é um protocolo de rede que permite o Acesso Remoto Direto à Memória (RDMA) através de redes Ethernet.
Quais aplicações que fazem o melhor uso do RDMA?
As aplicações que exigem baixa latência, alta vazão e baixa utilização da CPU para a comunicação de rede demandam funcionalidades como o RDMA, muito útil em cenários onde grandes volumes de dados precisam ser movidos rapidamente entre servidores ou entre dispositivos, como GPUs e adaptadores de rede:
Computação de Alto Desempenho (HPC – High Performance Computing):
Simulações Científicas: Experimentos que simulam fenômenos complexos, como mudanças climáticas, interações moleculares ou física de partículas, exigem um poder de processamento distribuído entre várias CPUs e GPUs. O RDMA acelera a comunicação entre esses nós, tornando as simulações mais rápidas e eficientes.
Clusters de Supercomputadores: Em ambientes de cluster, onde milhares de processadores trabalham em conjunto. O RDMA permite que os dados sejam transferidos diretamente entre as memórias dos nós, evitando gargalos e otimizando o desempenho geral do cluster.
Inteligência Artificial (IA) e Machine Learning (ML):
Treinamento de Redes Neurais: Modelos de IA, especialmente redes neurais profundas, exigem a transferência de grandes quantidades de dados (como pesos e gradientes) entre GPUs e outros dispositivos durante o treinamento. O RDMA acelera essas transferências, tornando o treinamento e a execução dos modelos mais rápidos e eficientes.
Análise de Dados em Larga Escala: Aplicações de IA e ML frequentemente lidam com conjuntos de dados massivos. O RDMA facilita o acesso e a movimentação desses dados, permitindo análises mais rápidas e em tempo real.
Armazenamento de Dados de Alta Performance:
Redes de Armazenamento (SANs e NAS): Soluções de armazenamento de alto desempenho, como NVMe over Fabrics (NVMe-oF), iSCSI Extensions for RDMA (iSER) e NFS over RDMA. Ele permite que os servidores acessem os dados diretamente na memória dos dispositivos de armazenamento, reduzindo a latência e aumentando a vazão.
Bancos de Dados In-Memory: Sistemas de banco de dados que mantêm os dados na memória para acesso ultrarrápido se beneficiam enormemente do RDMA, pois ele permite a replicação e o acesso rápido aos dados entre os nós do cluster.
Virtualização e Infraestrutura Hiperconvergente (HCI):
Comunicação entre Máquinas Virtuais (VMs): Em ambientes virtualizados, o RDMA pode otimizar a comunicação entre VMs, especialmente quando elas precisam trocar grandes volumes de dados.
HCI: Soluções de infraestrutura hiperconvergente, que integram computação, armazenamento e rede em uma única plataforma, se beneficiam do RDMA para garantir alta vazão e baixa latência na comunicação interna, fundamental para o desempenho geral do sistema.
Análise de Negócios (Business Analytics):
Aplicações que envolvem a análise de grandes volumes de dados para obter insights de negócios podem se beneficiar do RDMA para acelerar o processamento e a movimentação desses dados.
Replicação de Dados e Continuidade de Negócios:
O RDMA pode ser usado para replicação de dados de curta distância, oferecendo uma alternativa mais econômica e eficiente para soluções de recuperação de desastres (DR) e continuidade de negócios, especialmente em ambientes Ethernet.
Em resumo, qualquer aplicação que seja sensível à latência e que exija a transferência de grandes volumes de dados entre sistemas se beneficiará significativamente do RDMA. A capacidade de descarregar o processamento da rede da CPU e mover dados diretamente entre as memórias dos dispositivos é o que torna o RDMA uma tecnologia tão valiosa nesses cenários.
Tecnologias para uso do RDMA em redes Ethernet Convergentes
Tradicionalmente, para enviar dados, as aplicações precisam passar pelo sistema operacional para empacotar o TCP/IP, e então pelos caches da memória principal e da placa de rede, antes de serem enviados. Esse processo introduz latência e consome recursos da CPU.
O RoCE (RDMA over Converged Ethernet), por sua vez, permite que as tarefas de envio e recebimento de pacotes sejam transferidas para a placa de rede (NIC), eliminando a necessidade de o sistema entrar no modo kernel, característico do protocolo TCP/IP. Isso reduz a sobrecarga associada à cópia, encapsulamento e desencapsulamento de dados, resultando em uma diminuição substancial na latência da comunicação Ethernet e minimizando a utilização de recursos da CPU durante a comunicação.
Vantagens do RoCE:
Alta performance: Proporciona acesso remoto à memória com alta largura de banda e baixa latência.
Suporte a RDMA: Permite a transferência direta de dados entre memórias sem envolver a CPU do host, o que reduz a sobrecarga de processamento e aumenta a eficiência.
Custo-benefício: Permite alcançar um desempenho similar ao InfiniBand (outra tecnologia RDMA de alta performance) em redes Ethernet existentes, que geralmente são mais acessíveis.
Compatibilidade: Funciona sobre a infraestrutura Ethernet, facilitando a integração em configurações de data center já existentes.
Versões do RoCE:
Existem duas versões principais do protocolo RoCE:
RoCE v1: É um protocolo da camada de enlace Ethernet, o que significa que a comunicação é limitada a hosts dentro do mesmo domínio de broadcast Ethernet.
RoCE v2: É um protocolo da camada de internet, o que permite que os pacotes RoCE v2 sejam roteados e possam viajar entre sub-redes. Ele opera sobre UDP/IPv4 ou UDP/IPv6.
Para que o RoCE funcione de forma otimizada, é importante que a rede Ethernet seja “lossless” (sem perdas), o que geralmente é configurado através de controle de fluxo Ethernet ou controle de fluxo de prioridade (PFC).
O RoCE é amplamente utilizado em cenários que exigem alta performance e baixa latência, como data centers, computação de alto desempenho (HPC), inteligência artificial (IA), aprendizado de máquina e redes de armazenamento.
Detalhando um pouco mais o RoCEv1 e RoCEv2
A distinção entre RoCEv1 e RoCEv2 reside na sua camada de operação e, consequentemente, na sua capacidade de roteamento.
O RoCEv1 é um protocolo que atua na Camada 2 da rede, a camada de enlace de dados. Isso significa que sua comunicação é restrita ao mesmo domínio de broadcast Ethernet, ou seja, a mesma VLAN ou sub-rede. Ele não possui a capacidade de ser roteado por dispositivos de Camada 3, como roteadores. Sua implantação é mais simples, mas sua flexibilidade é limitada a ambientes de rede mais planos ou a segmentos isolados.
Por outro lado, o RoCEv2 opera na Camada 3, a camada de rede. Ele encapsula os pacotes RDMA dentro de pacotes UDP e IP. Essa característica é a sua maior vantagem, pois permite que os pacotes RoCEv2 sejam roteados através de roteadores de Camada 3. Isso possibilita a comunicação RDMA entre diferentes sub-redes e até mesmo através de redes de longa distância, embora o desempenho em WANs possa ser afetado pela latência. O cabeçalho do pacote RoCEv2 é um pouco mais complexo, incluindo os cabeçalhos UDP e IP, além do cabeçalho InfiniBand, o que adiciona um pequeno overhead.
Em termos de flexibilidade e escalabilidade, o RoCEv1 é menos versátil, sendo mais adequado para clusters menores ou segmentos de rede isolados. Já o RoCEv2 é significativamente mais flexível e escalável, tornando-se a escolha preferencial para data centers modernos e ambientes de nuvem que demandam comunicação RDMA entre múltiplos segmentos de rede. A configuração de rede para o RoCEv2 é mais elaborada, pois envolve o endereçamento IP e o roteamento, além da necessidade de garantir uma rede sem perdas com PFC e ECN.
Na prática, o RoCEv2 é a versão predominante e a mais recomendada para novas implementações de RDMA sobre Ethernet, dada a sua capacidade de roteamento e a flexibilidade que oferece para construir redes de alto desempenho em larga escala. O RoCEv1 ainda pode ser encontrado em algumas configurações mais antigas ou em situações muito específicas onde a comunicação é estritamente local.
Como já explicado, o RoCE é uma tecnologia baseada em Ethernet. Sua primeira versão (v1) utiliza regras do InfiniBand (IB) na camada de rede, enquanto a segunda versão (v2) emprega UDP e IP, permitindo que os pacotes de dados sejam transmitidos por diferentes caminhos de rede. O RoCE pode ser visto como uma versão mais econômica do InfiniBand (IB), pois encapsula as informações do IB em pacotes Ethernet para transmissão e recepção.
Como o RoCEv2 pode utilizar equipamentos de comutação Ethernet comuns (embora exija suporte a tecnologias de controle de fluxo como PFC e ECN para lidar com problemas de congestionamento e perda de pacotes na Ethernet), ele tem aplicação mais ampla em empresas. No entanto, em condições convencionais, seu desempenho pode não ser tão bom quanto o do IB.
iWARP
iWARP (Internet Wide Area RDMA Protocol) é uma tecnologia que permite o Acesso Remoto Direto à Memória (RDMA) sobre redes Ethernet padrão, utilizando os protocolos TCP/IP. Diferente do RoCE, que requer uma rede Ethernet “lossless” e switches com configurações específicas para controle de fluxo (PFC/ECN), o iWARP é projetado para funcionar sobre a infraestrutura TCP/IP existente, o que o torna mais fácil de implantar em redes convencionais sem a necessidade de alterações significativas nos switches. Ele alcança o RDMA descarregando as operações TCP/IP para a placa de rede (NIC), permitindo que os dados sejam transferidos diretamente para a memória remota sem a intervenção da CPU do host, resultando em baixa latência e alta vazão, embora geralmente com um desempenho ligeiramente inferior ao RoCE em ambientes otimizados, devido à sobrecarga inerente ao TCP/IP.
O protocolo iWARP é baseado no TCP, um protocolo confiável e orientado a conexão. Isso significa que, na presença de problemas de rede (como perda de pacotes), o iWARP é mais confiável que o RoCEv2 e o InfiniBand (IB), especialmente em redes de grande escala. No entanto, estabelecer um grande número de conexões TCP pode consumir memória significativa, e os mecanismos complexos do TCP, como controle de fluxo, podem impactar o desempenho. Portanto, em termos de desempenho, o iWARP pode não ser tão eficiente quanto o RoCEv2 e o IB, que são baseados em UDP.
Consorcio UEC
O Consórcio UEC propõe substituir o ROCEv2 por um novo protocolo aberto baseado em UDP/IP, focado em redes de IA/ML e HPC. O protocolo substituto deve oferecer multipath, controle de congestionamento eficiente, escalabilidade e confiabilidade, exigindo mudanças em todas as camadas da pilha de rede. Detalhes estão no whitepaper do UEC, que compartilha ideias com trabalhos como o 1RMA Paper e o EDQS Paper. A expectativa é que novidades sobre a tecnologia do UltraEthernet Consortium sejam divulgadas no Open Compute Global Summit em outubro.
Atualmente, não há um padrão ROCEv3 em desenvolvimento, e as demandas de IA/ML, HPC e datacenters em nuvem podem exigir soluções distintas devido a diferenças em latência, throughput e topologias de rede. Embora haja a possibilidade de um padrão único e programável, a colaboração entre fóruns será essencial para evitar fragmentação. O processo de maturação de novos padrões é lento, envolvendo anos de desenvolvimento e testes, enquanto grandes players continuam a investir em soluções proprietárias no curto prazo.
O EVE-NG (Emulated Virtual Environment – Next Generation) é uma plataforma de virtualização usada para emular redes, dispositivos e sistemas operacionais, permitindo a criação de laboratórios complexos para testes e estudos em TI. Suportando uma variedade de imagens de dispositivos de rede (como Aruba, Cisco, Juniper, Fortinet e outros), o EVE-NG é amplamente utilizado por profissionais e estudantes para simular topologias de rede realistas sem a necessidade de hardware físico. Com uma interface web intuitiva, integração com ferramentas como Wireshark e capacidade de executar máquinas virtuais, o EVE-NG se destaca como uma solução eficiente para treinamento, certificações e desenvolvimento de projetos de redes.
A ferramenta esta disponível em versões Community (gratuita) e Professional (paga), a ferramenta é compatível com diversos hipervisores como VMware e KVM.
A Aruba disponibiliza laboratórios guiados para a configuração dos Switches Aruba CX Estes documentos irão guiá-lo através de alguns cenários e tecnologias típicos de funcionalidades do AOS-CX. Sinta-se à vontade para baixá-los, implementá-los e depois fazer alterações, variações e melhorias:
A arquitetura Gen7 da HPE Aruba representa um avanço significativo no design de ASICs para redes, superando várias limitações das gerações anteriores. Diferente dos modelos tradicionais com pipelines fixos – que impõem restrições rígidas ao processamento de pacotes – esta nova abordagem introduz maior flexibilidade na manipulação de tráfego. A implementação de mecanismos como Virtual Output Queuing (VoQ) e alocação dinâmica de TCAM que permite um gerenciamento mais eficiente dos recursos de hardware, especialmente em cenários com tráfego heterogêneo.
Do ponto de vista técnico, a principal inovação está na capacidade de adaptação dinâmica. Um chip ASIC ou Circuito Integrado de Aplicação Específica é uma peça especial que é fabricada para executar apenas uma função específica e não pode ter seu funcionamento alterado posteriormente. Enquanto ASICs convencionais exigem reinicializações para reconfigurações profundas, o Gen7 possibilita ajustes em tempo real em parâmetros como QoS e ACLs. Essa característica se mostra particularmente relevante em ambientes com requisitos variáveis, onde a rigidez arquitetural tradicional frequentemente resulta em subutilização de recursos ou necessidade de overprovisioning.
A transição para arquiteturas mais flexíveis reflete uma mudança mais ampla nas demandas das infraestruturas de rede. Com a crescente diversificação de cargas de trabalho e a adoção de novas tecnologias, a capacidade de reconfiguração dinâmica tornou-se um requisito fundamental. Essa evolução não elimina completamente os desafios de projeto – ainda existem trade-offs entre flexibilidade e desempenho bruto – mas oferece um caminho mais sustentável para a evolução das redes corporativas.
O resultado disso é mais estabilidade, confiabilidade e melhor utilização dos recursos de hardware pelo software. Além disso, o Gen 7 inclui alta performance, incluindo VOQ (Virtual Output Queuing) – uma tecnologia que evita o head-of-line blocking e otimiza o fluxo de tráfego nos switches de rede. Esse recurso, comum em switches de data center, também está disponível no ambiente corporativo, como nos modelos CX 6400 e CX 6300.
Por fim, os ASICs oferecem programabilidade flexível, que dependendo do modelo de implantação, do caso de uso e do ambiente, é possível ajustar e programar dinamicamente o ASIC para atender às necessidades específicas.
O VOQ (Virtual Output Queuing) é um mecanismo avançado de gerenciamento de filas em switches e roteadores, projetado para eliminar o problema de head-of-line blocking (HOL blocking) – um gargalo comum em arquiteturas de rede tradicionais.
Como Funciona?
Filas Dedicadas por Porta de Saída
Em switches convencionais, os pacotes são armazenados em uma única fila compartilhada, podendo causar congestionamento se um pacote à frente estiver esperando por uma porta ocupada.
No VOQ, cada porta de saída tem sua própria fila virtual no buffer de entrada. Assim, pacotes destinados a portas diferentes não competem pelo mesmo espaço.
Eliminação do HOL Blocking
Se um pacote não pode ser encaminhado imediatamente (por exemplo, se a porta de destino está ocupada), somente essa fila específica é bloqueada, enquanto pacotes para outras portas continuam fluindo.
Alocação Dinâmica de Largura de Banda
O VOQ permite agendamento inteligente (usando algoritmos como Round Robin ou Weighted Fair Queuing) para priorizar tráfego crítico e otimizar a utilização do switch.
Vantagens do VOQ
Permite maior eficiência na comutação (evita desperdício de largura de banda devido a bloqueios), permite baixa latência (pacotes não ficam presos atrás de outros em filas compartilhadas), oferece justiça no tráfego (prevê starvation, onde alguns fluxos monopolizam a banda) e escalabilidade (essencial para data centers e redes de alta capacidade)
Aplicações Típicas
Data Centers (evita congestionamento em switches spine-leaf)
Redes Corporativas (melhora desempenho em cenários com múltiplos serviços, como VoIP e vídeo)
Switches Programáveis (usado em ASICs modernos)
Comparação com Arquiteturas Tradicionais
Modelo Tradicional
VOQ
Uma fila compartilhada por entrada
Múltiplas filas virtuais (uma por porta de saída)
Risco alto de HOL blocking
Elimina HOL blocking
Ineficiência em tráfego assimétrico
Alta eficiência mesmo com cargas desbalanceadas
Imaginando que o switch é um grande organizador de tráfego de dados, e o VOQ (Virtual Output Queuing) é seu sistema de filas inteligentes. Em vez de uma única fila “desorganizada”, ele cria filas separadas e organizadas para cada destino, evitando congestionamentos no encaminhamento do tráfego.
O tráfego é dividido em dois tipos Unicast e Flood.
No final, o switch usa um sistema de pesos para decidir quanto de cada tipo de tráfego envia – mantendo tudo equilibrado, sem deixar ninguém esperando demais.
Geralmente, para o tráfego unicast, cada módulo de entrada contém oito VOQs por porta de destino (uma para cada nível de prioridade). O perfil da fila define qual VOQ armazena cada pacote, enquanto o perfil de agendamento determina a ordem de transmissão. Os pacotes aguardam nas VOQs até serem selecionados pelo scheduler para cruzar o fabric do switch, sendo temporariamente armazenados em uma fila de transmissão reduzida na porta de saída. Já o tráfego flood (broadcast, multicast e unknown-unicast) segue um caminho separado, com oito VOQs por módulo de destino, onde cópias dos pacotes são replicadas para cada módulo alvo antes da transmissão.
O agendamento final combina ambas as filas (unicast e flood) usando um algoritmo Weighted Fair Queuing (WFQ). Esse scheduler atribui um peso fixo, como por exemplo, de 4 para tráfego unicast e 1 para flood, assegurando que pacotes replicados representem cerca de 20% do tráfego total quando ambas as filas estão ativas. Essa abordagem equilibra eficiência e justiça, priorizando tráfego direcionado sem negligenciar a entrega multidestino (flood).
As tecnologias de virtualização e computação em nuvem vem tomando espaço nos Data Centers e alterando assim a sugestão do modelo tradicional do modelo rede de três camadas Core, Agregação e Acesso.
O modelo tradicional de 3 camadas é eficiente para o tráfego “Norte-Sul”, onde o tráfego percorre o caminho de dentro para fora do Data Center. Este tipo de tráfego é tipicamente utilizado em serviços web, como exemplo, podemos citar o tráfego norte-sul onde há grande volume no modelo de comunicação cliente remoto/servidor.
Esse tipo de arquitetura tradicional é normalmente construído para redundância e resiliência contra falhas em equipamentos ou cabos, organizando portas de bloqueio pelo protocolo Spanning-Tree (STP), a fim de evitar loops de rede.
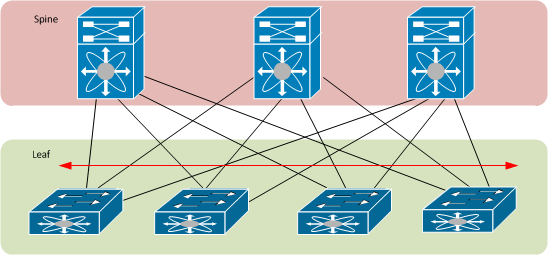
A arquitetura Spine Leaf é uma maneira inteligente de organizar redes em data centers. Ela é ótima para ambientes que precisam de alto desempenho e baixa latência. As tendências da comunicação entre máquinas nos Data Centers exigem uma arquitetura que sustente as demandas para o tráfego “Leste-Oeste”, ou tráfego de servidor para servidor.
Dependo da configuração lógica do “antigo” modelo tradicional de 3 camadas, o tráfego poderia atravessar todas as camadas para chegar no host de destino entre máquinas no mesmo Data Center, podendo introduzir dessa maneira uma latência imprevisível ou mesmo falta de largura de banda nos uplinks.
A arquitetura leaf-spine é uma topologia de rede escalável e de alta performance, amplamente utilizada em data centers. Ela é composta por duas camadas principais: a camada leaf (folha), que consiste em switches de acesso conectados diretamente aos servidores ou dispositivos finais, e a camada spine (espinha), formada por switches de núcleo que interconectam todos os switches leaf. Cada switch leaf está conectado a todos os switches spine, criando uma malha completa que oferece múltiplos caminhos entre qualquer par de dispositivos na rede. Essa estrutura é projetada para evitar loops naturalmente, já que os switches leaf não se conectam diretamente entre si, nem os switches spine se interligam, eliminando a possibilidade de caminhos redundantes que possam causar loops.
Para gerenciar o encaminhamento de dados e garantir a prevenção de loops, a arquitetura leaf-spine utiliza protocolos de roteamento modernos, como BGP (Border Gateway Protocol) ou OSPF (Open Shortest Path First), em vez de protocolos tradicionais como o Spanning Tree Protocol (STP). Esses protocolos são capazes de calcular os melhores caminhos com base em métricas, evitando loops de forma eficiente. Além disso, a rede aproveita todos os links ativos por meio de técnicas como o Equal-Cost Multi-Path (ECMP), que distribui o tráfego de forma equilibrada entre os múltiplos caminhos disponíveis. Como todos os caminhos entre leaf e spine têm o mesmo custo (geralmente um número fixo de saltos), o ECMP permite que o tráfego seja balanceado, maximizando a utilização da largura de banda e evitando gargalos.
Essa combinação de prevenção de loops e utilização de todos os links ativos traz diversas vantagens, como alta disponibilidade, baixa latência e escalabilidade. A rede se torna mais resiliente a falhas, pois, se um link ou switch falhar, o tráfego pode ser redirecionado instantaneamente por outros caminhos. A latência é mantida baixa, já que o número de saltos entre qualquer par de dispositivos é sempre o mesmo (normalmente dois saltos: leaf → spine → leaf). Além disso, a arquitetura permite a adição de novos switches leaf ou spine sem interromper o funcionamento da rede, tornando-a ideal para ambientes de data center que exigem alta performance, escalabilidade e confiabilidade.
VxLAN e BGP EVPN
A arquitetura leaf-spine também pode ser aprimorada com a integração de tecnologias como VXLAN (Virtual Extensible LAN) e BGP EVPN (Ethernet VPN), que ampliam sua funcionalidade e eficiência em ambientes de data center modernos. O VXLAN permite a criação de redes overlay sobre a infraestrutura física, encapsulando tráfego de camada 2 em pacotes de camada 3, o que possibilita a extensão de redes locais virtuais (VLANs) além dos limites físicos tradicionais. Já o BGP EVPN atua como protocolo de controle, fornecendo uma maneira eficiente de gerenciar a distribuição de informações de rede e a conectividade entre os dispositivos.
A combinação de VXLAN com BGP EVPN traz benefícios significativos, como a simplificação da segmentação de rede, a melhoria da escalabilidade e a facilitação da migração de cargas de trabalho entre diferentes ambientes. Com o BGP EVPN, a rede pode gerenciar de forma dinâmica os endereços MAC e as informações de roteamento, reduzindo a complexidade operacional e permitindo uma melhor utilização dos recursos. Além disso, essa integração suporta cenários de multi-tenancy, onde múltiplos clientes ou aplicações podem compartilhar a mesma infraestrutura física de forma segura e isolada.
Ao adotar VXLAN com BGP EVPN em uma arquitetura leaf-spine, a rede se torna ainda mais robusta e adaptável, capaz de suportar demandas modernas como virtualização, cloud computing e mobilidade de workloads. Essa combinação não apenas mantém as vantagens já existentes da topologia leaf-spine, como prevenção de loops e uso eficiente de links, mas também adiciona camadas de flexibilidade e controle, tornando-a uma solução ideal para data centers de próxima geração.
Vantagens da arquitetura spine leaf em data centers modernos
A arquitetura Spine Leaf é uma opção interessante para data centers modernos, oferecendo várias vantagens. Aqui estão alguns pontos importantes a considerar:
Redução de latência: Isso significa que os dados são transferidos mais rapidamente, resultando em uma experiência mais ágil para os usuários.
Facilidade de expansão: Você pode adicionar novos dispositivos com facilidade, sem complicações, quando seu negócio cresce.
Gerenciamento de tráfego: Essa arquitetura ajuda a evitar sobrecarga nas redes, melhorando a eficiência.
Otimização de recursos: Garante que a largura de banda esteja disponível quando você realmente precisa dela.
Automação nas redes spine leaf
Quando falamos sobre automação e segurança em redes, especialmente na Arquitetura leaf-spine, é importante lembrar como essas ferramentas podem facilitar o dia a dia. Imagine ajustar diversas configurações em poucos cliques, ao invés de gastar horas na configuração de cada equipamento. Isso não só economiza tempo, mas também minimiza erros humanos. Além disso, a segurança é fundamental: com o aumento das ameaças digitais, ter camadas de proteção, como segmentação, firewalls e monitoramento constante, é essencial para proteger os dados. Criar zonas seguras dentro da rede ajuda na detecção de comportamentos estranhos.
Gerenciamento de oversubscription e configuração de switches
Gerenciar a oversubscription é fundamental na Arquitetura Spine Leaf. Basicamente, isso significa conectar mais dispositivos do que a largura de banda permite. Isso pode funcionar bem se for planejado corretamente. Aqui estão alguns pontos a considerar:
Relação de oversubscription: Defina uma relação adequada com base na sua carga de trabalho. Por exemplo, uma relação de 4:1 pode ser ideal para certos cenários.
Configuração dos links: Ajuste bem os links entre os switches spine e leaf para garantir eficiência e reduzir o risco de lentidão.
Monitoramento constante: Acompanhe o tráfego para detectar possíveis gargalos antes que eles se tornem problemas sérios.
Antes de projetar uma arquitetura leaf-spine, é importante saber quais são as necessidades futuras e atuais. Por exemplo, se você tem um número de 100 servidores e que poderá escalar até 500, você precisa ter certeza de o Fabric poderá ser dimensionado para acomodar as necessidades futuras. Há duas variáveis importantes para calcular a sua escalabilidade máxima: o número de uplinks em um switch leaf e o número de portas nos switches spine. O número de uplinks em um switch leaf determina quantos Switches spine você terá no fabric.
Já os equipamentos de WAN podem ser posicionados em um Switch leaf separado para esse fim, nomeado como border-leaf.
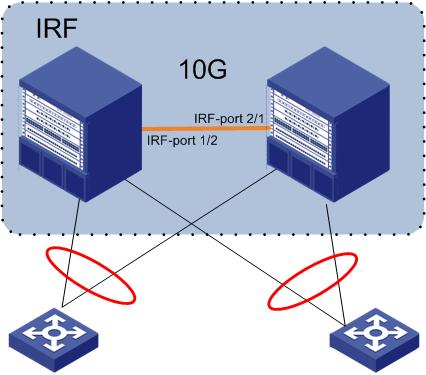
O protocolo IRF v2 permite o “empilhamento” de Switches modulares e empilháveis (stackable), trazendo inúmeras vantagens como redundância, facilidade no gerenciamento, etc.
O IRF pode trazer problemas quando há a quebra do Link 10G que mantém o IRF ativo, essa quebra é chamada de SPLIT. Quando um equipamento percebe que o Master não está respondendo ele assume as suas funções, e nesse caso, com os 2 equipamentos funcionando, ocorrerá a duplicação de alguns serviços e trazendo diversos conflitos na Rede(lembrando que apenas a fibra que sincroniza as informações para o IRF foi danificada).
Publicamos alguns posts no blog com a configuração de proteção para que os equipamentos percebam quando ocorre um SPLIT e bloqueiem um dos equipamentos colocando-o em estado de Recovery, deixando todas as portas inutilizáveis.
É possível utilizar features como BFP e o LACP para monitoração do IRF v2 e escolher algumas interfaces mais críticas para continuarem encaminhando no caso de falha no cabo que conecta o IRF.
Um detalhe importante a ser percebido é que após a correção do SPLIT (com reparo do cabo 10G danificado) o Switch que estava em estado de Recovery reiniciará automaticamente para efetuar o merge (junção) novamente no IRF. Segue abaixo as saídas após a quebra do IRF
[Switch]
#May 29 04:12:18:253 2000 Switch IFNET/4/INTERFACE UPDOWN:
Trap 1.3.6.1.6.3.1.1.5.3: Interface 11796529 is Down,
ifAdminStatus is 1, ifOperStatus is 2
%May 29 04:12:18:254 2000 Switch IFNET/3/LINK_UPDOWN:
Ten-GigabitEthernet1/0/50 link status is DOWN.
System is busy with VIU configuration recovery, please wait a moment...
[Switch]disp mad verbose
Current MAD status: Recovery
Excluded ports(configurable):
Excluded ports(can not be configured):
Ten-GigabitEthernet1/0/50
MAD ARP disabled.
MAD LACP disabled.
MAD BFD enabled interface:
Vlan-interface10
mad ip address 192.168.1. 1 255.255.255.252 member 1
mad ip address 192.168.1. 2 255.255.255.252 member 2
! Após reconectarmos as portas do IRF o Switch reiniciará automaticamente
%May 29 04:13:55:028 2000 Switch STM/6/STM_LINK_STATUS_UP:
IRF port 2 is up.
O IRF (Intelligent Resilient Framework) é uma tecnologia de virtualização de switches com o sistema Comware que permite interconectar múltiplos switches físicos, transformando-os em um único switch lógico.
Uma das coisas bacanas da utilização do IRF é a possibilidade de transformarmos diversos Switches físicos em um único Switch lógico facilitando o modo de gerenciamento. Todos os equipamentos serão visualizados como uma única “caixa”. Na versão 2 do protocolo é possível efetuar o Stacking utilizando links de 10G.
O “split brain” é um problema crítico que pode ocorrer em tecnologias de clusterização ou virtualização de dispositivos, como o IRF (Intelligent Resilient Framework) em switches Comware e ocorre quando a comunicação entre os membros do cluster é interrompida, fazendo com que cada parte do cluster passe a operar como um sistema independente, acreditando ser o único ativo. No contexto do IRF, isso significa que cada conjunto de switches isolados passa a se comportar como um switch lógico separado.
Para prevenir o split brain, o IRF utiliza o mecanismo MAD (Multi-Active Detection). O MAD monitora a conectividade entre os membros do IRF e toma medidas para evitar problemas em caso de falha na comunicação.
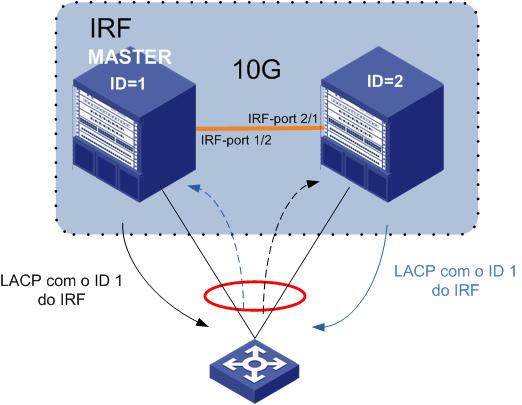
Como o LACP se integra ao MAD?
O LACP pode ser usado como um método de detecção MAD, oferecendo uma camada extra de proteção. A ideia principal é usar os pacotes LACP trocados entre os switches do IRF e um switch intermediário (ou outro dispositivo de rede) para monitorar a integridade da conexão.
Uma das features que podem ser utilizadas nesse cenário é a utilização de Link Aggregation distribuído (Ditribuited Link Aggregation) entre os equipamentos do IRF com Switches de acesso (sem configuração adicional no Link Aggregation).
Se um Switch empilhado apresentar algum problema, como por exemplo, problemas elétricos, o(s) outro(s) Switches serão capazes de permitir a continuidade do encaminhamento em Camada 2 e 3 (incluindo processos de Roteamento Dinâmico).
Porém, um dos problemas que o IRF pode trazer é quando ocorre uma quebra do Link 10G que mantém o IRF ativo, chamado de SPLIT. Cada caixa ira agir como se fosse o MASTER do IRF, duplicando alguns serviços e trazendo diversos conflitos na Rede.
O MAD é uma das formas para os Switches do Stack detectarem que houve o SPLIT no IRF colocando o Equipamento com o maior Member ID do IRF (não Master) em modo Recovery, bloqueando assim todas as suas portas.
Após restaurado o Link do IRF as portas serão vinculadas novamente o Stack e ao seu estado normal de encaminhamento.
Uma das formas utilizadas pelo MAD para detecção de falha é utilizando uma extensão do protocolo LACP ( Link Aggregation). No TLV do protocolo é inserido o ID do Switch membro do IRF. Nesse caso os Switches da outra ponta do Link Aggregation, encaminham de forma transparente os LACP’s para os Switches Membros do IRF.
Como no exemplo acima, se não há SPLIT no IRF, todas mensagens serão geradas pelo ID do MASTER.
Em caso de quebra do SPLIT as mensagens serão geradas com o ID de cada equipamento e nesse caso o bloqueio das portas do não-Master.
Após detecção as portas bloqueadas do IRF pelo LACP com MAD.
Configuração
A configuração abaixo deverá ser aplicada somente no Switch com o IRF versão 2 “já ativo”.
[S7500]interface bridge-aggregation 1
!Criando a Interface Bridge-Aggregation 1
[S7500-Bridge-Aggregation1] link-aggregation mode dynamic
! Ativando a troca do protocol LACP no Link Aggregation
[S7500-Bridge-Aggregation1] mad enable
! Ativando a extensão MAD no protocol LACP
[S7500-Bridge-Aggregation1] quit
[S7500] interface gigabitethernet 1/3/0/2
[S7500-GigabitEthernet1/3/0/2] port link-aggregation group 1
!Adicionando a interface ao Link Aggregation 1
[S7500-GigabitEthernet1/3/0/2] quit
[S7500] interface gigabitethernet 2/3/0/2
[S7500-GigabitEthernet2/3/0/2] port link-aggregation group 1
!Adicionando a interface ao Link Aggregation 1
[S7500-GigabitEthernet2/3/0/2] quit
Obs: Os switches de acesso conectados ao IRF pelo Link Aggregation não necessitam da configuração do MAD. Mas o fabricante sugere que esse Switch seja um equipamento H3C.
“Requires an intermediate switch, which must be an H3C switch that supports the extended LACP.”
Comandos Display
S7500] display mad
MAD LACP enabled.
Comando display após SPLIT do IRF no Switch não Master
[S7500]display mad verbose
Current MAD status: Recovery
! Switch não-Master em modo recovery após perceber o SPLIT no IRF
! (bloqueando todas as portas)
…………………………
MAD enabled aggregation port:
Bridge-Aggregation1
Obs: o modo Recovery também permite excluímos algumas portas para que continuem em estado de encaminhamento. Há também um segundo modo de utilizar o MAD para detecção de SPLIT utilizando o Protocolo BFD.